电话咨询:400-811-8890
电话咨询:400-811-8890
电话咨询:400-811-8890
电话咨询:400-811-8890
作者:Jenny.Zhang
发布时间:2022.11.1
浏览次数:4,832 次浏览
一个优秀的数据分析师,除了要掌握基本的统计学、数据库、数据分析方法、思维、数据分析工具技能之外,还需要掌握一些数据挖掘的思想,帮助我们挖掘出有价值的数据,这也是数据分析专家和一般数据分析师的差距之一。

数据挖掘主要分为分类算法,聚类算法和关联规则三大类,这三类基本上涵盖了目前商业市场对算法的所有需求。而这三类里又包含许多经典算法。
由于网上上很多关于数据挖掘算法的介绍都十分的深奥难懂,今天我就给大家用简单的大白话来介绍一下数据挖掘十大经典算法原理,帮助大家快速理解。
(1)核心思想
当一篇论文被引用的次数越多,证明这篇论文的影响力越大。同理可引申为一个网页的入口越多,入链越优质,网页的质量越高。
(2)原理
网页影响力=阻尼影响力+所有入链集合页面的加权影响力之和
用户并不都是按照跳转链接的方式来上网,还有其他的方式,比如直接输入网址访问,所以需要设定阻尼因子,代表了用户按照跳转链接来上网的概率。
(3)比喻说明
微博:一个人的微博粉丝数不一定等于他的实际影响力,还需要看粉丝的质量如何。如果是僵尸粉没什么用,但如果是很多大V或者明星关注,影响力很高。
店铺的经营:顾客比较多的店铺质量比较好,但是要看看顾客是不是托。
兴趣:在感兴趣的人或事身上投入了相对多的时间,对其相关的人事物也会投入一定的时间。那个人或事,被关注的越多,它的影响力/受众也就越大。
(4)关于阻尼因子
(5)出链例子
hao123导航网页,出链极多入链极少。
(6)入链例子
百度谷歌等搜索引擎,入链极多出链极少。
(1)核心思想
关联关系挖掘,从消费者交易记录中发掘商品与商品之间的关联关系。
(2)原理
支持度
某个商品组合出现的次数与总次数之间的比例。5次购买,4次买了牛奶,牛奶的支持度为4/5=0.8。5次购买,3次买了牛奶+面包,牛奶+面包的支持度为3/5=0.6。
置信度
购买了商品A,有多大概率购买商品B,A发生的情况下B发生的概率是多少。买了4次牛奶,其中2次买了啤酒,(牛奶->啤酒)的置信度为2/4=0.5。买了3次啤酒,其中2次买了牛奶,(啤酒->牛奶)的置信度为2/3-0.67。
提升度
衡量商品A的出现,对商品B的出现 概率提升的程度。提升度(A->B)=置信度(A->B)/支持度(B)。提升度>1,有提升;提升度=1,无变化;提升度<1,下降。
频繁项集
项集:可以是单个商品,也可以是商品组合。频繁项集是支持度大于最小支持度(Min Support)的项集。
(3)计算过程
(4)比喻说明:啤酒和尿不湿摆在一起销售
沃尔玛通过数据分析发现,美国有婴儿的家庭中,一般是母亲在家照顾孩子,父亲去超市买尿不湿。父亲在购买尿不湿时,常常会顺便搭配几瓶啤酒来犒劳自己,于是,超市尝试推出了将啤酒和尿不湿摆在一起的促销手段,这个举措居然使尿不湿和啤酒的销量都大幅增加。
(1)原理
简单的说,多个弱分类器训练成为一个强分类器。将一系列的弱分类器以不同的权重比组合作为最终分类选择。
(2)计算过程
(3)比喻说明
利用错题提升学习效率
做正确的题,下次少做点,反正都会了。做错的题,下次多做点,集中在错题上。随着学习的深入,做错的题会越来越少。
合理跨界提高盈利
苹果公司,软硬结合,占据了大部分的手机市场利润,两个领域的知识结合起来产生新收益。
(1)核心思想
决策就是对于一个问题,有多个答案,选择答案的过程就是决策。C4.5算法是用于产生决策树的算法,主要用于分类。C4.5使用信息增益率做计算(ID3算法使用信息增益做计算)。
(2)原理
C4.5选择最有效的方式对样本集进行分裂,分裂规则是分析所有属性的信息增益率。信息增益率越大,意味着这个特征分类的能力越强,我们就要优先选择这个特征做分类。
(3)比喻说明:挑西瓜。
拿到一个西瓜,先判断它的纹路,如果很模糊,就认为这不是好瓜,如果它清晰,就认为它是一个好瓜,如果它稍稍模糊,就考虑它的密度,密度大于某个值,就认为它是好瓜,否则就是坏瓜。
(1)概念介绍
CART
Classification And Regression Tree,中文叫分类回归树,即可以做分类也可以做回归。
什么是分类树、回归树?
回归问题和分类问题的本质一样,都是针对一个输入做出一个输出预测,其区别在于输出变量的类型。
(2)原理
CART分类树
与C4.5算法类似,只是属性选择的指标是基尼系数。基尼系数反应了样本的不确定度,基尼系数越小,说明样本之间的差异性小,不确定程度低。分类是一个不确定度降低的过程,CART在构造分类树的时候会选择基尼系数最小的属性作为属性的划分。
CART 回归树
采用均方误差或绝对值误差为标准,选取均方误差或绝对值误差最小的特征。
(3)比喻说明
(1)核心思想
朴素贝叶斯是一种简单有效的常用分类算法,计算未知物体出现的条件下各个类别出现的概率,取概率最大的分类。
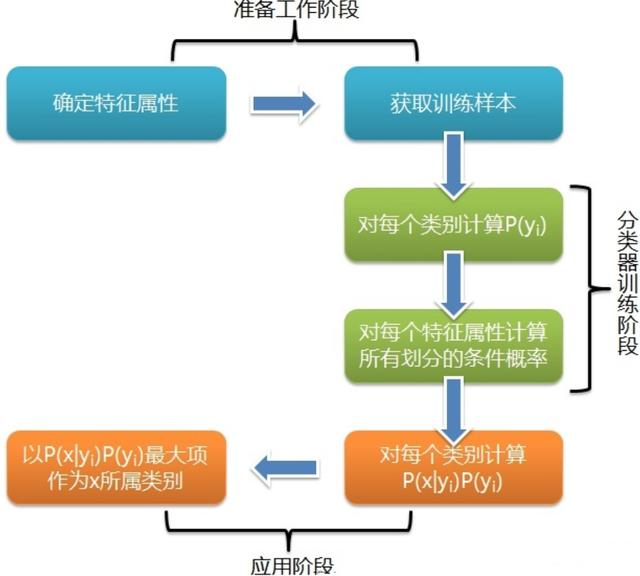
(2)原理
假设输入的不同特征之间是独立的,基于概率论原理,通过先验概率P(A)、P(B)和条件概率推算出后概率出P(A|B)。
(3)比喻说明:给病人分类。

给定一个新病人,是一个打喷嚏的建筑工人,计算他患感冒的概率。
(1)概念介绍
SVM
Support Vector Machine,中文名为支持向量机,是常见的一种分类方法,最初是为二分类问题设计的,在机器学习中,SVM 是有监督的学习模型。
什么是有监督学习和无监督学习 ?
(2)原理
找到具有最小间隔的样本点,然后拟合出一个到这些样本点距离和最大的线段/平面。
(3)比喻说明
(1)核心思想
机器学习算法中最基础、最简单的算法之一,既能分类也能回归,通过测量不同特征值之间的距离来进行分类。
(2)原理
计算待分类物体与其他物体之间的距离,对于K个最近的邻居,所占数量最多的类别,预测为该分类对象的类别。
(3)计算步骤
(4)比喻说明:近朱者赤,近墨者黑。
(1)核心思想
K-means是一个聚类算法,是无监督学习,生成指定K个类,把每个对象分配给距离最近的聚类中心。

(2)原理
(3)比喻说明
选老大
大家随机选K个老大,谁离得近,就是那个队列的人(计算距离,距离近的人聚合在一起)。随着时间的推移,老大的位置在变化(根据算法,重新计算中心点),直到选出真正的中心老大(重复,直到准确率最高)。
Kmeans和Knn的区别
Kmeans开班选老大,风水轮流转,直到选出最佳中心老大。Knn小弟加队伍,离那个班相对近,就是那个班的。
(1)核心思想
EM 的英文是 Expectation Maximization,所以 EM 算法也叫最大期望算法,也是聚类算法的一种。
EM和K-Means的区别:
(2)原理
先估计一个大概率的可能参数,然后再根据数据不断地进行调整,直到找到最终的确认参数。
(3)比喻说明:菜称重。
很少有人用称对菜进行称重,再计算一半的分量进行平分。大部分人的方法是:
10大算法都已经说完了,其实一般来说,常用算法都已经被封装到库中了,只要new出相应的模型即可。

商业智能BI产品更多介绍:www.finebi.com