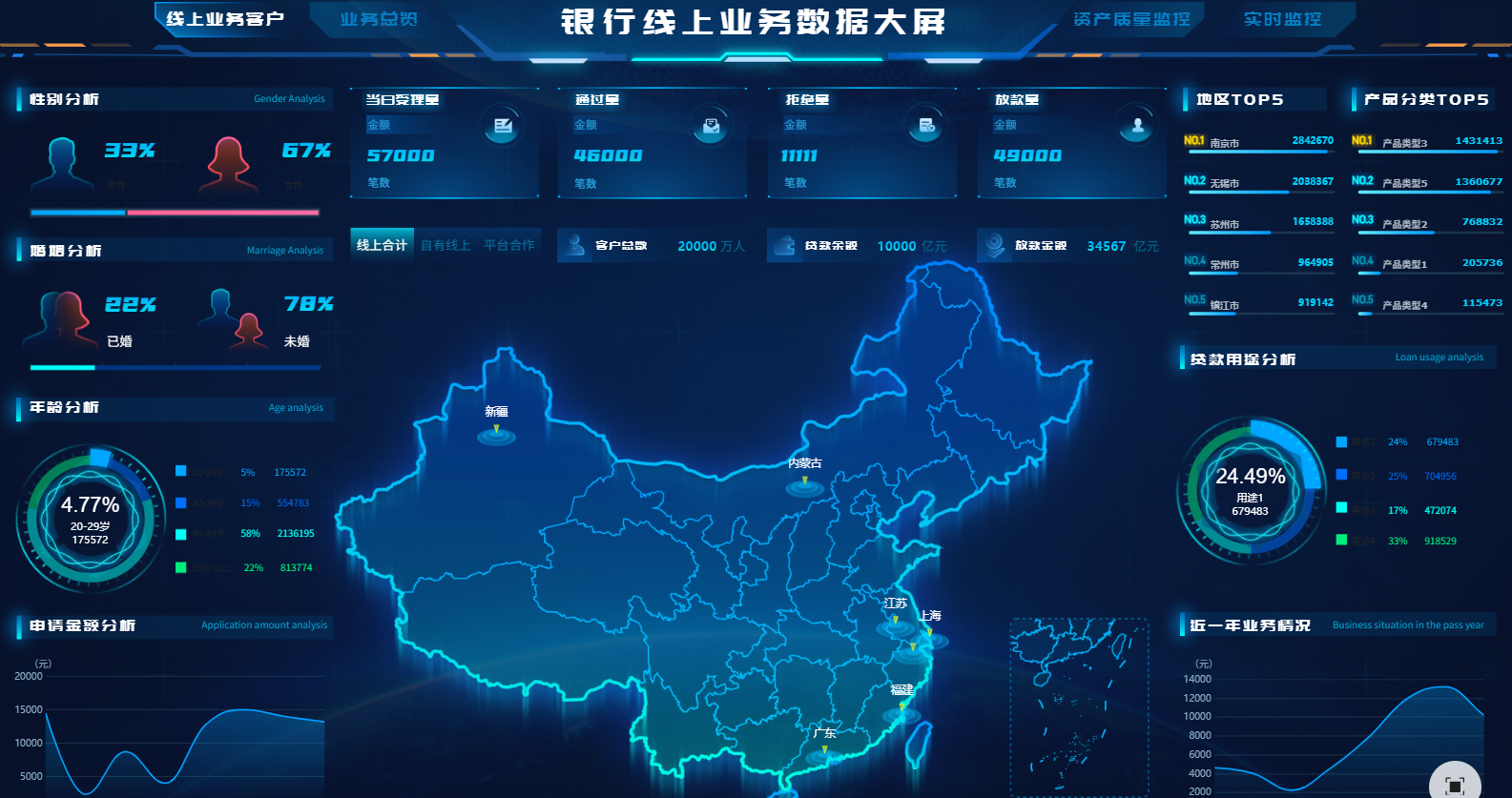
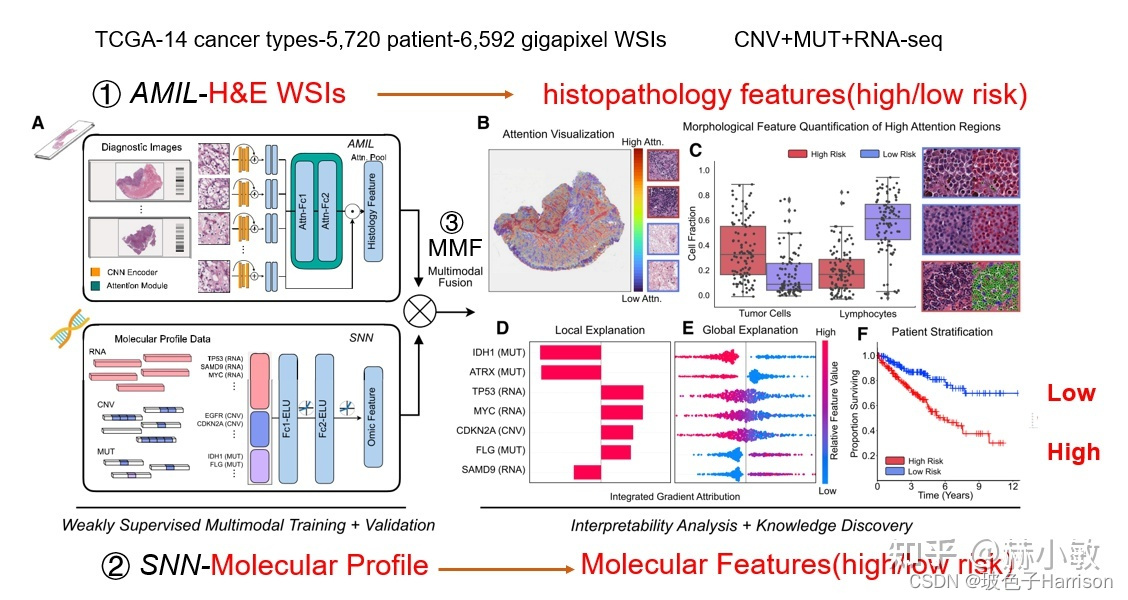
在大数据时代,企业面临的一个主要挑战是如何有效地运用统计模型来从海量数据中提取有价值的信息。然而,构建和优化统计模型并非易事,涉及许多技术壁垒和实践难点。本文将深入探讨这些难点,并提供切实可行的优化策略,帮助企业在竞争激烈的市场中脱颖而出。通过引用实际案例和权威文献,这篇文章将为数据科学家和业务决策者提供实用的指导。

🚀 一、理解统计模型中的主要难点
统计模型的构建过程中,往往会遇到一些常见的挑战,这些挑战可能影响模型的准确性和实用性。以下是三个主要难点及其细分要点。
🎯 1. 数据质量与数据预处理
数据质量是统计模型成功与否的基石。高质量的数据能提高模型的准确性,而不良数据则会导致误导性的结果。数据预处理是改善数据质量的关键步骤,包括数据清洗、处理缺失值、以及特征选择。
数据清洗与处理缺失值
数据清洗是数据预处理中最基本的步骤。它包括去除噪声数据、纠正错误数据、以及处理重复数据等。处理缺失值的方法有删除法、插值法和模型预测法等,这些方法各有其适用场景和优缺点。
特征选择与特征工程
特征选择是指从原始数据中选择对模型预测结果影响最大的特征。这一步骤可以降低模型的复杂性,提高模型的泛化能力。特征工程则是通过数据转换、特征组合等方法来提升模型性能。
| 步骤 | 方法 | 优势 |
|---|---|---|
| 数据清洗 | 去噪声、纠错 | 提高数据真实性和一致性 |
| 处理缺失值 | 插值、预测 | 保持数据完整性,减少信息损失 |
| 特征选择 | 过滤法、包裹法 | 提高模型效率,减少过拟合 |
| 特征工程 | 变换、组合 | 提升模型性能,揭示潜在关系 |
- 数据清洗:保持数据的一致性与真实性。
- 处理缺失值:完整的数据能带来更可靠的分析。
- 特征选择和工程:通过简化数据增强模型的预测能力。
📊 2. 模型选择与参数调优
在模型选择中,必须考虑模型的复杂性与适用性。选择合适的模型可以显著提高预测的准确性。参数调优则是为了在特定数据集上达到最佳性能。
模型选择的策略
模型选择常常依赖于数据的特性和业务需求。线性模型适用于线性关系明显的数据,而非线性模型则适合复杂的、非线性的模式。常用的模型包括线性回归、决策树、支持向量机等。
参数调优的重要性
参数调优能够极大地影响模型的性能。常用的调优方法有网格搜索和随机搜索。通过交叉验证来评估模型在不同参数下的表现,选出最佳参数组合。
| 模型类型 | 特点 | 适用场景 |
|---|---|---|
| 线性模型 | 简单、可解释性强 | 线性关系明显的数据 |
| 非线性模型 | 复杂、适应性强 | 模式复杂、非线性关系的数据 |
| 参数调优方法 | 网格搜索、随机搜索 | 提升模型性能,适用于所有模型类型 |
- 模型选择:根据数据特性选择适合的模型类型。
- 参数调优:通过优化参数组合来提升模型表现。
🔍 3. 模型评估与验证
模型评估是模型构建过程中的重要环节,用于衡量模型的性能和可靠性。常用的评估指标包括准确率、精确率、召回率、F1值等。
评估指标的选择
不同的业务场景对模型有不同的性能要求,选择合适的评估指标能够更好地反映模型的实际表现。例如,在信用卡欺诈检测中,精确率和召回率比准确率更为重要。
交叉验证与过拟合
交叉验证是一种常用的模型验证方法,可以有效地防止过拟合。通过将数据集划分为训练集和验证集,交叉验证能够提供更稳定的模型性能评估。
| 评估方法 | 优势 | 适用场景 |
|---|---|---|
| 准确率 | 简单易懂 | 分类任务 |
| 精确率、召回率 | 平衡正负样本 | 不平衡数据集 |
| 交叉验证 | 防止过拟合,稳定评估结果 | 所有数据集 |
- 评估指标选择:根据业务需求选择合适的评估指标。
- 交叉验证:防止过拟合,确保模型的泛化能力。
📈 二、优化统计模型的实践策略
在明确统计模型的难点后,接下来我们将探讨如何通过优化实践策略来突破这些难点,提升模型的性能和应用价值。
⚙️ 1. 自动化数据处理
自动化数据处理是提升模型效率的重要手段。通过自动化工具和脚本,可以大大减少人工干预,提高数据处理的速度和准确性。
数据清洗自动化
自动化数据清洗可以利用机器学习的异常检测算法来识别并修复数据中的异常值和错误数据。通过自动化脚本,能够实现批量数据的高效清洗。
特征工程自动化
自动化特征工程通过算法自动生成和选择特征,减少了人为选择的主观性和复杂性。常用的方法包括特征生成算法和特征选择算法。
| 自动化步骤 | 方法 | 优势 |
|---|---|---|
| 数据清洗 | 异常检测 | 提高清洗效率,减少人工干预 |
| 特征工程 | 算法生成 | 降低复杂性,提升特征选择的科学性 |
- 自动化数据清洗:通过异常检测提高数据处理效率。
- 特征工程自动化:减少复杂性,提升特征生成的科学性。
🛠 2. 模型集成与组合
模型集成是通过组合多个模型来获得更好的预测性能。集成学习能够在单一模型的基础上,通过不同模型的组合,提升整体预测效果。
模型集成方法
常用的模型集成方法包括Bagging、Boosting和Stacking等。这些方法通过不同的策略组合模型,以提高预测的准确性和稳定性。
集成学习的优点
集成学习能有效减少模型的方差和偏差,提升模型的泛化能力。它能够更好地处理复杂数据和解决过拟合问题。
| 集成方法 | 特点 | 适用场景 |
|---|---|---|
| Bagging | 降低方差,提升稳定性 | 数据噪声较大的场景 |
| Boosting | 减少偏差,提高准确性 | 偏差较大的模型 |
| Stacking | 综合多个模型的优点 | 综合性预测任务 |
- Bagging:通过减少方差提高模型稳定性。
- Boosting:通过减少偏差提升模型准确性。
- Stacking:结合多个模型的优点进行综合预测。
🔧 3. 持续监控与优化
模型的构建和优化并不是一劳永逸的过程。持续监控和优化是保持模型性能的关键。
模型监控的重要性
通过对模型预测结果的持续监控,可以及时发现模型性能的下降和数据分布的变化。利用监控工具和指标,可以快速定位问题,进行调整和优化。
模型的迭代优化
在模型性能下降或数据分布发生显著变化时,需要进行模型的迭代优化。可以通过调整模型参数、更新训练数据集等方式来保持模型的高效性。
| 优化步骤 | 方法 | 优势 |
|---|---|---|
| 持续监控 | 监控工具 | 快速发现问题,及时调整 |
| 迭代优化 | 参数调整 | 保持模型的高效性和适应性 |
- 持续监控:通过监控工具及时发现模型问题。
- 迭代优化:通过参数调整保持模型的高效性。
📚 参考文献
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer.
- Géron, A. (2019). Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems. O'Reilly Media.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
📝 结论
统计模型在数据分析中扮演着重要角色,但其构建和优化过程常常面临许多挑战。通过理解数据质量、模型选择、参数调优等难点,并采用自动化数据处理、模型集成、持续监控等优化策略,企业可以显著提升模型的性能和应用价值。希望本文提供的策略和建议能为企业在统计模型的应用中提供有力支持,帮助您更好地驾驭数据的力量。
本文相关FAQs
📊 什么是统计模型中最常见的难点?如何理解和突破这些难点?
老板总是问我,能不能用统计模型预测市场趋势?我也想用好这些工具,但一碰到那些复杂的数学公式和概念就头疼。有没有大佬能分享一下,如何从零开始理解这些统计模型的核心难点?
统计模型的核心难点常常在于其数学复杂性和数据需求。很多初学者在面对一系列复杂的数学公式和统计假设时容易感到不知所措。一个常见的问题是如何选择合适的模型,因为不同的模型适用于不同的数据结构和业务需求。比如,线性回归适合处理线性关系的数据,而决策树则更灵活,不需要假设数据的分布。
理解这些难点的突破口在于:
- 基础概念的掌握: 从概率论和统计学的基本概念入手,比如正态分布、均值、方差等。
- 模型的选择与假设: 理解每种模型背后的假设条件以及其适用场景。比如,线性回归要求变量之间有线性关系。
- 数据预处理的重要性: 数据的质量直接影响模型的表现,因此数据的清洗、处理和特征选择是关键步骤。
- 模型验证与优化: 学会使用交叉验证、过拟合检查等手段来评估模型的性能。
通过这些步骤,初学者可以逐步克服对统计模型的恐惧,进而在实际项目中应用这些工具。
🛠 如何优化统计模型的实践策略?有没有高效的方法?
我在项目中尝试用统计模型来分析用户数据,但发现模型效果并不理想。有没有具体的策略可以帮助我优化这些模型,提升数据分析的准确性?
优化统计模型的实践策略常常需要从多个角度进行考虑。模型的表现不理想可能是因为数据预处理不充分、模型选择不当或参数调整不够精细等问题。以下是一些高效的优化方法:
优化统计模型的策略:
- 数据质量提升: 确保数据的完整性和准确性,包括处理缺失值、去除异常值和归一化处理。
- 特征工程: 提取和选择合适的特征,这通常比选择合适的模型更重要。可以使用PCA进行降维,或通过交叉特征来提升模型的表现。
- 模型选择和组合: 不同的模型有不同的优势,可以通过模型组合(如集成学习)来提升整体性能。
- 参数调整: 使用网格搜索或随机搜索对模型参数进行调优,以找到最优的参数组合。
此外,FineBI作为自助大数据分析工具,提供了友好的可视化分析界面和多种数据处理功能,可以帮助用户快速搭建统计模型并进行优化。 FineBI在线试用 。
🤔 统计模型优化后如何验证效果?有哪些评估指标?
经过一番努力,我对统计模型进行了优化,但总感觉效果不太稳定。有没有什么方法可以验证模型的改进效果?应该关注哪些评估指标?
验证统计模型的效果是数据分析工作中的重要环节。优化后的模型需要通过科学的评估指标来判定其改进效果。常用的评估指标包括准确率、召回率、F1分数等,对于回归模型,则可能关注均方误差(MSE)和决定系数(R²)。
验证模型效果的步骤:
- 划分数据集: 使用训练集、验证集和测试集来分别进行模型的训练、调优和最终验证。
- 选择合适的评估指标: 根据业务需求选择合适的指标。例如,在分类问题中,可能更关注F1分数以平衡精确率和召回率。
- 交叉验证: 通过K折交叉验证来确保模型的稳定性和泛化能力。
- 可视化分析: 利用混淆矩阵、ROC曲线等工具来直观展示模型的表现。
通过这些方法,可以更全面地评估统计模型的优化效果,确保其在实际应用中的可靠性和稳定性。
%20by%20%E2%80%9ELisa%20Wischofsky%E2%80%9D%2C%20licensed%20under%20%E2%80%9ECC0%201.0%E2%80%9D%20(https%3A%2F%2Fcreativecommons.org%2Fpublicdomain%2Fzero%2F1.0%2F)%3C%2Fdc%3Arights%3E%3C%2Frdf%3ADescription%3E%3C%2Frdf%3ARDF%3E%3C%2Fmetadata%3E%3Cmask%20id%3D%22viewboxMask%22%3E%3Crect%20width%3D%22980%22%20height%3D%22980%22%20rx%3D%220%22%20ry%3D%220%22%20x%3D%220%22%20y%3D%220%22%20fill%3D%22%23fff%22%20%2F%3E%3C%2Fmask%3E%3Cg%20mask%3D%22url(%23viewboxMask)%22%3E%3Crect%20fill%3D%22%23b6e3f4%22%20width%3D%22980%22%20height%3D%22980%22%20x%3D%220%22%20y%3D%220%22%20%2F%3E%3Cg%20transform%3D%22translate(10%20-60)%22%3E%3Cpath%20d%3D%22M498%20134c4%200%208%200%2012%202%203%201%204%205%203%208-1%202-4%204-7%205l-8%209a98%2098%200%200%201%2062%201c14%205%2028%2012%2040%2021%2010%207%2020%2015%2031%2021%2014%208%2030%2014%2046%2017l40%208c19%203%2037%208%2054%2017%2015%207%2030%2016%2040%2029%207%2010%209%2022%205%2034-5%2011-15%2019-22%2029-2%204-6%209-6%2013%201%205%206%209%209%2012l34%2019c8%205%2015%2011%2020%2019%206%207%209%2016%208%2025%200%206-2%2013-5%2018-3%207-10%2012-16%2017l-21%2022c-6%208-11%2020-7%2030%202%205%204%2011%2010%2013l21%2010c23%2015%2038%2043%2038%2071%200%2019-7%2037-20%2051a62%2062%200%200%201-47%2018c-4-1-8-1-12%201-6%202-9%209-9%2016%202%2014%208%2027%2011%2041%202%2010%202%2021-1%2032-3%208-7%2016-13%2022-7%206-16%2010-26%2010-11%200-21-5-32-8a58%2058%200%200%200-51%2015c0%208%204%2016%2012%2020%203%202%206%201%2010%201%202%200%203%203%203%205-1%205-3%2010-6%2014a104%20104%200%200%201-54%2030l-15%201c-9%201-19%200-29-1-24-2-49-6-74-7-12%200-25%203-37%204l-17%204-29%204a264%20264%200%200%201-103-15c-9-4-17-8-23-15-8-7-12-18-12-28l4-24c1-4%201-10-2-13-4-5-10-9-16-10-8-2-17-3-23-8-7-4-9-12-9-19-1-12%204-23%2010-34l20-31%204-12%205-40c-9-5-19-10-27-17-6-4-10-9-14-15a72%2072%200%200%201-15-44c-1-7%201-15-2-22-2-8-8-12-12-19l-15-20c-6-10-10-22-13-33-7-26-8-54%200-79%207-21%2019-40%2035-55l34-28%2011-14c5-10%208-20%2015-29%208-14%2023-24%2038-29%207-2%2015-4%2022-3%208%202%2015%204%2022%208a150%20150%200%200%201%2080-87c13-5%2027-9%2041-8Z%22%20fill%3D%22%23000000%22%2F%3E%3Cpath%20d%3D%22M495%20231a231%20231%200%200%201%20219%20204c1%2010%202%2021%200%2030-1%204-1%207-4%208-3-10-3-19-4-29a220%20220%200%200%200-239-205c-42%204-83%2019-117%2044l-17%2013a221%20221%200%200%200-78%20164c0%2023%207%2043%2015%2064h17c3%201%204%204%202%206l-6%202c-15%201-31%207-42%2017-8%209-14%2019-16%2031-3%2015%200%2032%208%2045%209%2015%2024%2027%2040%2033%2014%205%2029%207%2043%205%204-1%208-2%2011%200v3c-5%205-11%206-18%207-16%203-33-1-47-8a86%2086%200%200%201-47-58c-4-18-1-37%209-53%208-12%2020-21%2034-26-7-14-10-28-12-43-2-18-2-35%200-53%201-13%204-25%208-38a227%20227%200%200%201%2099-122c41-28%2092-43%20142-41Z%22%20fill%3D%22%23000%22%2F%3E%3Cpath%20d%3D%22M535%20244a220%20220%200%200%201%20171%20200c1%2010%201%2019%204%2029l-2%2018v22c-3%204-4%209-4%2014-2%208-2%2015-2%2023v65c0%2021-3%2042-11%2061-4%2013-10%2024-18%2035-10%2012-21%2022-34%2031-11%209-24%2017-37%2024l-22%2014-12%208%209-2c-3%2011-3%2024-4%2036%200%208%201%2016%207%2022a235%20235%200%200%200%2081%2045c6%207%2011%2016%2013%2025%201%209%200%2018-4%2027-6%2010-14%2018-23%2024-13%2010-28%2017-43%2022a417%20417%200%200%201-217%2011c-16-3-33-9-48-17-10-5-21-12-28-21-6-6-10-14-11-22-2-10%200-21%205-30%2021-13%2039-32%2049-54%205-11%207-22%208-34%201-16%200-32-1-47-2-20-3-41-8-61%2011%2012%2023%2024%2037%2032%2017%2011%2036%2020%2055%2026%2020%207%2041%2013%2063%2018l25%203c3%200%206%200%208-2%202-1%201-2%202-3l-17-2c-29-7-58-16-87-27-18-7-36-15-53-27-18-13-33-30-47-47l-11-16-1-1v-3c-3-2-7-1-11%200-14%202-29%200-43-5-16-6-31-18-40-33-8-13-11-30-8-45%202-12%208-22%2016-31%2011-10%2027-16%2042-17l6-2c2-2%201-5-2-6h-17c-8-21-15-41-15-64-1-14%202-27%205-41a221%20221%200%200%201%2073-123l17-13a230%20230%200%200%201%20185-39Z%22%20fill%3D%22%23ffffff%22%2F%3E%3Cpath%20d%3D%22M708%20513c3%203%202%207%203%2012v29c0%2026%202%2054%200%2080-3%2031-14%2063-36%2086-25%2028-57%2051-93%2064l2%207v35c1%206%204%2010%208%2014l26%2019%2032%2020%2024%2012c2%200%203%201%205%203l-19-5c-19-6-37-14-54-25-9-5-19-12-26-20-6-6-7-14-7-22%201-12%201-25%204-36l-9%202%2012-8%2022-14c13-7%2026-15%2037-24%2013-9%2024-19%2034-31a178%20178%200%200%200%2029-96v-65c0-8%200-15%202-23%200-5%201-10%204-14ZM278%20574c5%205%204%2014%200%2019l-3%207c1%203%205%205%207%206%206%203%2012%207%2019%209%200%204-3%205-7%205-6-1-13-3-18-6-7-3-13-8-13-16%200-6%205-9%206-14%202-4%200-7-1-11%204-1%207-2%2010%201ZM328%20667l11%2016c14%2017%2029%2034%2047%2047%2017%2012%2035%2020%2053%2027a714%20714%200%200%200%20104%2029c-1%201%200%202-2%203-2%202-5%202-8%202l-25-3a478%20478%200%200%201-118-44c-14-8-26-20-37-32%205%2020%206%2041%208%2061%201%2015%202%2031%201%2047-1%2012-3%2023-8%2034-10%2022-28%2041-49%2054l-14%208c2-4%206-6%209-9%2013-11%2024-25%2034-39%206-10%2012-21%2014-33%204-19%203-39%203-58l-3-59%202-10c-10-11-19-26-22-41Z%22%20fill%3D%22%23000%22%2F%3E%3Cpath%20d%3D%22M473%20484c4-2%2010-1%2013%203%205%204%208%2011%208%2017%202%2010%200%2021-4%2030-3%206-6%2012-13%2014-6%202-14-1-17-7-5-6-6-15-6-22%201-8%202-16%206-24%203-5%207-9%2013-11ZM643%20491c4-2%209-2%2013%202%205%204%207%2012%207%2018%201%209-1%2018-5%2025-2%205-6%208-11%2010-5%201-11-1-14-5-3-3-5-7-6-12-1-9%201-18%204-26%203-5%206-10%2012-12Z%22%20fill%3D%22%23000000%22%2F%3E%3Cpath%20d%3D%22M467%20377c15%201%2032%205%2044%2015%204%203%208%207%209%2011%201%203%201%205-2%206-3%200-6-3-8-5-11-8-24-13-38-13-8%200-15%202-23%204-15%203-29%2011-38%2023-3%203-5%207-10%208s-10-3-10-8c-1-4%202-8%204-11%2012-15%2030-25%2049-29%207-2%2015-2%2023-1ZM672%20387c5%202%2010%207%2013%2011%203%203%205%207%205%2011%200%206-6%2010-12%208-5-2-6-7-10-11-4-3-9-7-13-8-12-4-24%201-32%209l-9%209c0-7%204-13%209-17%2012-13%2032-18%2049-12Z%22%20fill%3D%22%23000000%22%2F%3E%3Cpath%20d%3D%22M216%20569c5%200%2010-1%2014%202%203%202%205%205%204%209-2%204-6%207-11%207h-16c-5-1-9-3-11-7-1-4%202-7%205-9%205-2%2010-1%2015-2ZM229%20592c3%201%207%203%207%207%200%203-1%206-4%207-5%204-11%204-17%206-5%201-10%202-14-1s-3-9%200-12c4-4%208-4%2013-5s10-3%2015-2ZM301%20644h8c3%201%206%204%206%208%200%205-4%209-9%2010-5%202-9-2-11-6-1-5%201-11%206-12Z%22%20fill%3D%22%23000000%22%2F%3E%3Cpath%20d%3D%22m591%20528%202%202%207%2022c4%208%2010%2015%2015%2023%204%206%206%2013%205%2020-1%206-4%2012-9%2016-7%207-16%2012-25%2016-5%203-11%204-17%202l5-4c11-9%2025-14%2036-24%202-2%204-6%204-9-1-7-5-11-8-16-5-9-10-16-13-25-2-7-4-16-2-23Z%22%20fill%3D%22%23000000%22%2F%3E%3Cpath%20d%3D%22M599%20665c5%200%2010%203%2013%207%203%206%204%2013%205%2020%201%2011-1%2023-6%2033-5%209-13%2013-22%2015-11%203-23%203-34%203-4%200-9-1-13-3%207-3%2013-3%2020-4l21-3c6-1%2014-4%2018-9s6-12%207-19l-4%206c-4%203-9%203-14%204l-26%204c-7%201-15%203-23%200l-11%2023c-3%201-3-2-3-4%200-7%203-14%206-20%207-17%2021-32%2036-42%209-6%2019-11%2030-11Z%22%20fill%3D%22%23000000%22%2F%3E%3Cpath%20d%3D%22M507%20135c3%200%206%202%207%206%200%204-4%206-6%208-4%202-7%205-10%209a99%2099%200%200%201%2060%201c15%205%2029%2012%2042%2021%2010%207%2021%2015%2032%2021%208%205%2017%209%2026%2012%2018%206%2036%208%2055%2012a226%20226%200%200%201%2082%2032c8%206%2015%2013%2019%2022%205%209%205%2021%200%2030-5%2010-14%2017-20%2026-2%204-6%209-6%2013%201%205%205%208%208%2011%2015%2011%2034%2017%2047%2030%2010%208%2017%2020%2016%2033%200%208-3%2017-8%2023-5%207-12%2013-18%2019-8%207-16%2015-21%2024-3%207-5%2017-1%2024%203%208%2012%2013%2019%2016%205%202%2010%204%2014%208%201%203%201%207-1%2010-5%206-13%2011-21%2013-16%205-33%204-49-1-13-3-24-8-34-16-9-6-16-15-21-25-10-16-13-35-14-54v-33l-1-6c-6-5-13-9-21-10-11-2-22-3-33-8-7-3-12-9-16-15s-5-13-7-20l-6-17c-1-4-5-8-10-11-4-3-10-2-14-1-7%203-14%205-22%205-15%200-31-2-45-10-8-5-14-13-17-22-4-7-4-14-6-22-6%208-12%2017-21%2023%205%2017%202%2035-7%2050-7%2013-17%2024-28%2034l-31%2022c-18%2013-36%2024-50%2041-6%209-13%2020-13%2031%200%206%204%209%206%2014%204%207%206%2017%205%2025-3%2011-12%2020-16%2030-3%209-5%2019-2%2028%202%208%207%2015%2014%2019l13%205h11c3%200%204%203%203%205l-5%208-17%207c-9%203-19%204-29%204-8%200-17-2-25-4-9-3-18-8-27-13-7-4-15-9-21-15a76%2076%200%200%201-24-60c0-6%200-11-2-17-2-8-8-12-12-19l-14-19a153%20153%200%200%201-15-108%20129%20129%200%200%201%2041-65l29-23c5-4%208-9%2011-15%206-9%209-19%2015-28%208-14%2023-24%2039-29%206-2%2014-4%2021-3%208%202%2015%204%2022%208a149%20149%200%200%201%2074-84c6-3%2012-6%2018-7%2012-4%2025-5%2038-3Z%22%20fill%3D%22%23000000%22%2F%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(10%20-60)%22%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fsvg%3E)
%20by%20%E2%80%9ELisa%20Wischofsky%E2%80%9D%2C%20licensed%20under%20%E2%80%9ECC0%201.0%E2%80%9D%20(https%3A%2F%2Fcreativecommons.org%2Fpublicdomain%2Fzero%2F1.0%2F)%3C%2Fdc%3Arights%3E%3C%2Frdf%3ADescription%3E%3C%2Frdf%3ARDF%3E%3C%2Fmetadata%3E%3Cmask%20id%3D%22viewboxMask%22%3E%3Crect%20width%3D%22980%22%20height%3D%22980%22%20rx%3D%220%22%20ry%3D%220%22%20x%3D%220%22%20y%3D%220%22%20fill%3D%22%23fff%22%20%2F%3E%3C%2Fmask%3E%3Cg%20mask%3D%22url(%23viewboxMask)%22%3E%3Crect%20fill%3D%22%23ffdfbf%22%20width%3D%22980%22%20height%3D%22980%22%20x%3D%220%22%20y%3D%220%22%20%2F%3E%3Cg%20transform%3D%22translate(10%20-60)%22%3E%3Cpath%20d%3D%22M663%20170c2%200%203%202%204%203%202%206%203%2012%202%2018%200%2017-6%2033-14%2048l10-3a86%2086%200%200%201%2068%2015c4%203%209%2010%208%2016l-3-1-12-8c-8-4-16-7-24-8-14-2-28-1-41%202%2016%205%2029%2014%2042%2024a172%20172%200%200%201%2053%2094c3%2014%204%2027%205%2041%201%2020-1%2042-2%2062%200%2016%201%2032%204%2048%203%2011%207%2021%2012%2030%207%2011%2014%2022%2023%2031%2011%2013%2024%2024%2032%2039%208%2016%2013%2034%2013%2052%200%2012-1%2024-5%2036-1%203-1%207-4%208-2%202-4%200-4-3%203-13%204-27%204-41-1-18-7-34-17-49s-26-25-39-39l11%2024%207%2014c12%2021%2018%2043%2021%2067%201%2013%201%2026-2%2038-2%209-6%2018-10%2026l-11%2013c-2%202-4%202-5%205-2%202-4%203-7%202-2-2-2-4-1-6%203-9%201-19-2-28-2%2013-7%2025-14%2035-9%2013-19%2025-32%2033-7%206-15%2011-23%2014-7%202-14%204-21%201-2%200-5%201-6-2v-11c-15%208-30%2016-46%2019-9%203-18%204-27%203-12%200-23-2-34-7-4-2-9-2-13-3-26-5-52-6-78-6-38-1-75%202-113%206l-17%201-17%201c-29%202-57%200-84-9-14-4-26-11-37-20-2%205-1%209-2%2014l-1%208c-3%203-7%203-10%202-8-2-13-7-19-12-9-6-16-15-20-25l-7-21c-4-18-2-36%200-54%202-15%204-30%208-44-9%2022-15%2047-17%2071-2%2023%202%2046%2010%2068%201%202%203%205%201%207h-4c-3-1-4-5-6-7a176%20176%200%200%201-11-78c2-25%209-49%2017-73l17-42c10-26%2018-51%2026-77%202-8%202-16%202-24l3-47c2-16%204-33%209-49l5-20c5-23%2015-45%2029-64%2020-28%2047-49%2076-66%2047-25%20100-38%20152-41%2044-1%2090%204%20131%2019a105%20105%200%200%200%2055-66l2-4Z%22%20fill%3D%22%23000000%22%2F%3E%3Cpath%20d%3D%22M486%20236c57-2%20115%2018%20159%2056a209%20209%200%200%201%2073%20190c-1%204-1%208-4%2012l-1-3v-33a215%20215%200%200%200-172-206%20235%20235%200%200%200-270%20153c-12%2037-14%2078-6%20116%206-2%2012-2%2017-2%202%201%205%201%206%203s0%203-1%204l-12%204c-14%203-27%208-37%2018a63%2063%200%200%200-22%2045c0%2012%203%2024%208%2035%208%2013%2019%2024%2033%2031%2018%2010%2041%2013%2062%207%202-1%204-2%206-1s3%204%204%206l15%2030a215%20215%200%200%200%2072%2063c28%2015%2059%2021%2090%2026%203%201%208%201%2010%204%201%202%200%203-2%204l-11%201a231%20231%200%200%201-147-62c5%2018%208%2036%208%2054%200%2012-2%2023-6%2034-5%2010-11%2018-19%2026a196%20196%200%200%201-60%2043c-1-1%201-2%202-3l17-14c13-12%2025-23%2035-38a93%2093%200%200%200%2017-65l-4-39-2-10-12-17c-5-10-11-20-13-31a93%2093%200%200%201-96-31%2081%2081%200%200%201-19-51c0-12%203-23%208-34%209-16%2023-29%2040-36-8-31-8-62-3-93%208-40%2026-77%2051-108%2045-54%20115-87%20186-88Z%22%20fill%3D%22%23000%22%2F%3E%3Cpath%20d%3D%22M541%20252a214%20214%200%200%201%20172%20206v33c-1%205-2%2010-1%2015-2%202-3%203-3%205-3%2018-1%2037%201%2055%204%2029%206%2059%202%2088-3%2028-13%2056-30%2079-16%2021-38%2034-62%2043-15%206-30%209-45%2013-11%202-22%204-32%208%201%202%204%201%206%202%2012%201%2024-1%2036-2-5%208-8%2017-9%2026-2%2010%202%2019%209%2026%206%207%2015%2011%2024%2014%205%202%2011%203%2017%203%207%209%2013%2018%2014%2030%202%2012-1%2024-8%2034-9%2014-22%2023-37%2030-18%209-38%2015-57%2018a352%20352%200%200%201-192-23c-18-10-38-23-48-42-4-7-8-16-6-24%2018-10%2033-23%2047-38%208-8%2014-16%2019-26%204-11%206-22%206-34%200-18-3-36-8-54a235%20235%200%200%200%20147%2062l11-1c2-1%203-2%202-4-2-3-7-3-10-4-31-5-62-11-90-26-18-10-36-22-50-37-8-8-16-17-22-26l-15-30c-1-2-2-5-4-6s-4%200-6%201a82%2082%200%200%201-95-38c-5-11-8-23-8-35%201-17%209-34%2022-45%2010-10%2023-15%2037-18l12-4c1-1%202-2%201-4s-4-2-6-3c-5%200-11%200-17%202-8-38-6-79%206-116a236%20236%200%200%201%20270-153Z%22%20fill%3D%22%23ffffff%22%2F%3E%3Cpath%20d%3D%22m712%20506%203%203%201%2013%203%2045c3%2020%205%2040%205%2060%200%2016-1%2032-5%2047-6%2028-20%2056-40%2076a174%20174%200%200%201-88%2046c-1%209-4%2016-4%2025-1%206%202%2010%205%2015%208%208%2018%2014%2028%2019l18%209c-3%203-8%201-12%202-6%200-12-1-17-3-9-3-18-7-24-14-7-7-11-16-9-26%201-9%204-18%209-26-12%201-24%203-36%202-2-1-5%200-6-2%2010-4%2021-6%2032-8%2015-4%2030-7%2045-13%2024-9%2046-22%2062-43%2017-23%2027-51%2030-79%204-29%202-59-2-88-2-18-4-37-1-55%200-2%201-3%203-5ZM262%20566c6%200%2012%201%2015%206%202%203%202%207%201%2010-3%208-9%2014-11%2022-1%204%200%207%203%209%207%205%2016%207%2024%2010l-2%202h-11c-6-1-12-2-17-5-5-4-9-11-7-18%202-9%209-15%2012-23-7-4-14-2-20-8%203-4%208-6%2013-5Z%22%20fill%3D%22%23000%22%2F%3E%3Cpath%20d%3D%22M668%20488c8%200%2016%204%2022%2010%202%203%205%208%204%2012%200%203-4%205-4%208-2%208-9%2014-16%2018-4%202-11%202-14-2-3-3-3-8-4-12%200-8%203-17%206-24-4%200-8%202-11%205-11%206-19%2017-24%2028-2%203-3%208-6%2010-1%201-3%201-4-1v-9c4-13%2012-25%2022-34%209-6%2019-9%2029-9ZM444%20498c20-1%2043%202%2060%2013%209%205%2017%2013%2020%2023%202%204%200%207-2%2011-2%203-7%205-11%207-12%203-24%201-36-1-5-1-11-2-14-6-4-5-3-11-1-17%201-7%203-14%209-20h-23c-17%202-33%209-47%2020-2%202-5%204-8%203-5%200-8-5-7-9s4-6%207-8c16-10%2035-14%2053-16Z%22%20fill%3D%22%23000000%22%2F%3E%3Cpath%20d%3D%22M479%20386c16%201%2033%207%2046%2017%203%203%207%205%208%209%201%202-1%205-3%204-8-1-15-5-23-7-7-3-15-5-23-5-7-1-15%200-22%201-15%202-30%209-43%2016l-21%209-1-1c1-4%203-9%206-12%206-10%2017-16%2027-21%2015-7%2032-11%2049-10ZM673%20390c5%202%2011%205%2015%2010%204%204%205%209%204%2015l-23-7c-7-2-13-1-20-2-7%200-15%201-21%205l-13%208h-3c-1-3%200-6%202-8%205-9%2013-15%2022-18%2012-4%2024-6%2037-3Z%22%20fill%3D%22%23000000%22%2F%3E%3Cpath%20d%3D%22M603%20613v1c-4%208-11%2015-20%2018-3%201-7%201-9-1v-4c7-5%2016-9%2024-12l5-2Z%22%20fill%3D%22%23000000%22%2F%3E%3Cpath%20fill-rule%3D%22evenodd%22%20clip-rule%3D%22evenodd%22%20d%3D%22m463%20648-14-4h-1c-2-1-5-1-6%201-1%201%200%203%201%203l6%203%202%201a257%20257%200%200%200%2073%2024c0%207%202%2014%207%2020%205%207%2012%2013%2021%2016%2010%204%2021%203%2031-1s18-12%2022-22c2-4%202-9%202-13l18-6v-1l2-2a1497%201497%200%200%200-29%200%20324%20324%200%200%201-86-4l-39-11-2-1-8-3Zm69%2029c1%2010%209%2018%2018%2023%2012%209%2032%205%2040-8%203-4%204-9%205-14v-1l-26%202%201%201c0%203%201%205-1%208s-6%203-7%200c-2-3-2-6-1-9a1036%201036%200%200%200-25-2h-4Z%22%20fill%3D%22%23000000%22%2F%3E%3Cpath%20d%3D%22m663%20170%204%203c2%205%202%2011%202%2016%200%2018-6%2035-15%2050%2013-4%2026-6%2040-4%2013%202%2028%206%2038%2016%205%204%2010%2010%209%2016l-6-3c-7-5-14-9-22-11-19-6-38-5-56%200l17%208c23%2013%2042%2032%2052%2056%205%2013%207%2026%204%2039s-9%2026-17%2036a151%20151%200%200%201-51%2042c-4%203-9%205-14%205l10-12c9-7%2015-18%2016-29%202-13%200-26-4-38-5-19-15-35-28-50%208%2027%206%2056-4%2081-6%2014-15%2026-26%2036-7%207-16%2013-26%2016-3%200-6%201-8-1l7-13c4-9%206-18%206-27%202-22-2-44-7-65l-6-18c1%2020-1%2039-8%2057a94%2094%200%200%201-61%2056c-4%201-9%203-13-1%206-4%2012-7%2017-12%209-6%2017-13%2024-21l11-18c8-16%2012-34%2012-52-2%2012-7%2023-12%2034-11%2019-24%2036-40%2051-14%2014-30%2025-49%2031-4%201-7%202-11%201l-4-2c0-7%203-13%204-19%204-16%207-32%207-48a181%20181%200%200%201-56%2065c-16%2011-32%2020-50%2027a253%20253%200%200%200-1%2089c4%2020%2014%2039%2027%2054l4%205c-6%200-9-4-13-7a97%2097%200%200%201-29-46c-1%2012%200%2024%201%2037%200%205%201%2010-1%2015l-4-3-11-7c-10-7-19-14-27-23-11-12-19-27-23-43l-3-6c-14-13-27-28-36-45-10-19-16-39-17-60-2-32%207-63%2024-90%2019-31%2048-55%2079-73a354%20354%200%200%201%20280-28c3%201%206%204%2010%202a102%20102%200%200%200%2052-63l2-6Z%22%20fill%3D%22%23000000%22%2F%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(10%20-60)%22%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fsvg%3E)
%20by%20%E2%80%9ELisa%20Wischofsky%E2%80%9D%2C%20licensed%20under%20%E2%80%9ECC%20BY%204.0%E2%80%9D%20(https%3A%2F%2Fcreativecommons.org%2Flicenses%2Fby%2F4.0%2F)%3C%2Fdc%3Arights%3E%3C%2Frdf%3ADescription%3E%3C%2Frdf%3ARDF%3E%3C%2Fmetadata%3E%3Cmask%20id%3D%22viewboxMask%22%3E%3Crect%20width%3D%22762%22%20height%3D%22762%22%20rx%3D%220%22%20ry%3D%220%22%20x%3D%220%22%20y%3D%220%22%20fill%3D%22%23fff%22%20%2F%3E%3C%2Fmask%3E%3Cg%20mask%3D%22url(%23viewboxMask)%22%3E%3Crect%20fill%3D%22%23c0aede%22%20width%3D%22762%22%20height%3D%22762%22%20x%3D%220%22%20y%3D%220%22%20%2F%3E%3Cpath%20d%3D%22M396%20164.8a224.8%20224.8%200%200%201%20104.8%2042.4c6.2%204.9%2012.5%209.4%2018%2015a225.4%20225.4%200%200%201%2071.8%20149%2058.5%2058.5%200%200%201%2050.9%2042.2%2071%2071%200%200%201-27.6%2076.5c-11%207.7-24.5%2012-38%2011.7-5%200-10-1.6-15-1.8-1.9%202.2-3.3%204.9-4.8%207.3A223.3%20223.3%200%200%201%20389%20609.8c-11%20.7-21.9%202-33%20.7a223.7%20223.7%200%200%201-178.8-342.3A223.4%20223.4%200%200%201%20352%20163.5c14.6-1.4%2029.4-.3%2044%201.3Z%22%20fill%3D%22%23000%22%2F%3E%3Cpath%20fill-rule%3D%22evenodd%22%20clip-rule%3D%22evenodd%22%20d%3D%22M498.8%20213.2A216%20216%200%200%200%20363%20169c-13-.2-26.2%201.6-39%204a218%20218%200%200%200-113.6%20365.5%20218.5%20218.5%200%200%200%20260.4%2040.2c35-18.8%2064.2-47.3%2084.4-81.5l-3-1.6c-2.8-1.4-5.7-3-8-5-2.2-2-.3-5.8%202.7-4.7%201.5.7%203%201.6%204.4%202.4a55%2055%200%200%200%2059.6-3.6%2064.5%2064.5%200%200%200%2025-69.8%2053.1%2053.1%200%200%200-24-31%2052.6%2052.6%200%200%200-47-2.8c-1.6.8-3.4%201.5-5%201.3-2.5-.2-2.8-4.2-.6-5.2%208-4%2016.5-5.6%2025.4-6.4a217%20217%200%200%200-72-146.4c-4.4-4-8.7-8.1-13.9-11.3Zm107.6%20196.2c2-1.2%201.3-5.1-1.4-5-2%200-4.2.8-6.2%201.6l-1.4.4a95.1%2095.1%200%200%200-25.5%2012.4c-2.2%202-2.2%204.4.1%206.2a92%2092%200%200%200%205.2%202.8%2036%2036%200%200%201%2013%209.2c-.2%201.9-2%203.4-3.4%204.5l-.2.2c-3.9%203-8.8%205-13.6%207-2.5%201-4.9%202-7.1%203.1-1.7.8-2.6%202.2-1.6%203.9%201%202%203.2%201.1%205%20.5l.6-.2%205.4-2.3c5.4-2.3%2011-4.5%2015.4-8%202.7-2.1%205.1-5.1%205.4-8.7-.5-3.4-2.7-5.7-5.3-7.8a83%2083%200%200%200-11.6-7.2l-1.1-.6c5.4-3%2010.8-5.6%2016.6-7.7l5-1.7a52%2052%200%200%200%206.7-2.6Z%22%20fill%3D%22%23f2d3b1%22%2F%3E%3Cg%20transform%3D%22translate(-161%20-83)%22%3E%3Cpath%20d%3D%22M574.5%20426.5a66.4%2066.4%200%200%201%2034%2022.7c7.5-5.1%2014.7-10.7%2022.4-15.7l3%201.3c-.3%202.1-.2%203.6-2.2%204.9l-20%2014.2a64.5%2064.5%200%200%201%209.8%2044c-.5%202.7-3%203.4-5.5%203.6-19.7%201-39.4%203-59%205.4-11%201.5-22.2%202-33.2%203.6l-13.6%201.8c-5%20.7-9.5%201.7-14.5.3a65.2%2065.2%200%200%201%2078.8-86.1Z%22%20fill%3D%22%23000%22%2F%3E%3Cpath%20d%3D%22M565.5%20430.4a59.8%2059.8%200%200%201%2050.7%2065.2c-4.7.4-9.5%201-14.2%201.2-18%201.2-36%203.3-53.8%205.4%201-3%202.2-6%202.5-9.2.8-9.3-4.1-18.8-12.3-23.4a25%2025%200%200%200-17.5-2.7%2024.5%2024.5%200%200%200-19.5%2025.1%2025%2025%200%200%200%206.3%2015.8l-7.3.7a59.3%2059.3%200%200%201%2035.4-74.9%2060.5%2060.5%200%200%201%2029.7-3.2Z%22%20fill%3D%22%23fff%22%2F%3E%3Cpath%20d%3D%22M416.5%20455.4a55%2055%200%200%201%2023.3%2061.7c-5.4%201-10.4.5-15.8.5-24-.2-48-.1-72%201.5-5.9-.1-12.6%201.6-17.8-1.2-1-4.6-2.1-9.2-2.3-13.9-.3-10%202.2-20%206.8-29-6-3.9-12.3-7.5-18.2-11.6-1.9-1.4-1.7-2.7-.8-4.7%202.7-1%204.5.5%206.8%201.8l15.2%209.8a55.3%2055.3%200%200%201%2074.8-14.9Z%22%20fill%3D%22%23000%22%2F%3E%3Cpath%20d%3D%22M400.8%20454.5a49.4%2049.4%200%200%201%2034.3%2057.9l-5.6.1a26%2026%200%200%200%202.9-14.5c-1-8.6-7.3-16.1-15.6-18.6a22%2022%200%200%200-28.5%2019.6c-.4%204.7%201%209%202.8%2013.2-13.4%200-26.8.6-40%201.6-3.8.2-8%20.7-11.6-.3-1.6-3-1.6-7.1-1.8-10.5a49.1%2049.1%200%200%201%2063.1-48.5Z%22%20fill%3D%22%23fff%22%2F%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(-161%20-83)%22%3E%3Cpath%20d%3D%22M607%20397.6c1.5-.4%203.2.6%204.7%201%200%201.2-.1%202.4-.4%203.6-1.6%201.5-3.6%202.6-5.4%203.8a803.6%20803.6%200%200%201-70.4%2040.6A289.9%20289.9%200%200%201%20500%20462a50%2050%200%200%201-21%203.5c-3.3-.4-6.2-3-6.2-6.5%200-4.2%203-8.6%205-12.1%201.3-2.7%204.5-3%207-4.1l111.7-41.5c3.5-1.2%207-2.8%2010.5-3.7ZM339%20432.6l90%2018c2.3.4%204.6.1%206.9.5%202.4%202.3%203.6%206.2%204.5%209.4%201.2%204-.1%208.8-4%2011-4%202.6-9.8%202.1-14.4%201.9-8.8-1-17.4-3.8-25.7-6.8a418%20418%200%200%201-57-27c-1.6-.9-3.6-1.9-4.8-3.5-.3-2.9%201.9-4.1%204.5-3.5Z%22%20fill%3D%22%23000%22%2F%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(-161%20-83)%22%3E%3Cpath%20d%3D%22m525%20563.7%201.2%202.3c.4%202.7-2%203.4-3.8%204.4a184%20184%200%200%201-85.8%2017c-5-.6-10.2-.7-15-2-2.3-1-2.6-4-.3-5.2%202.7%200%205.5.9%208.2%201%207.2%201%2014.3.7%2021.5.7%2022.5-.8%2045-6.8%2065.7-15.5%202.8-1.2%205.2-2.6%208.3-2.7Z%22%20fill%3D%22%23000%22%2F%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(-161%20-83)%22%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(-161%20-83)%22%3E%3Cpath%20fill-rule%3D%22evenodd%22%20clip-rule%3D%22evenodd%22%20d%3D%22M531.3%20506.7a27.9%2027.9%200%201%201-42.8%2024.6c-8.6-10.1-25.5-13.9-36.5-5.2-3.2%203-6.6%207.3-6.7%2011.9a27.5%2027.5%200%200%201-52.9%205.6%2027.6%2027.6%200%200%201%2010.5-32.7%2028%2028%200%200%201%2025.7-2.5%2028.6%2028.6%200%200%201%2016%2017.4%2027.2%2027.2%200%200%201%2022.4-10c8.2-.1%2015.4%203.2%2022%208a28%2028%200%200%201%2042.3-17Zm-22.6%202.4a22.4%2022.4%200%200%201%2029.9%2023c-.6%209.9-8.4%2018.2-18.1%2020.2a22.6%2022.6%200%200%201-25.9-16.3c-3-11.1%203.2-23%2014-26.9ZM438%20525a22%2022%200%200%200-23-12.8%2022%2022%200%200%200-12.6%2037.3c6.1%206%2015.8%208.1%2023.7%204.9%206.8-2.7%2012.2-9%2013.4-16.3.5-4.6.7-9-1.5-13.1Z%22%20fill%3D%22%23000%22%2F%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(-161%20-83)%22%3E%3Cg%20fill%3D%22%23000%22%3E%3Cpath%20d%3D%22M588%20235.8a209%20209%200%200%201%2042%204.8%20185.9%20185.9%200%200%201%2099.8%2058.6%20205%20205%200%200%201%2030.7%2051.3%20176.3%20176.3%200%200%201%2015.1%2062.5c1%2012.3.5%2024.8-1.2%2037-.9%205.4-.5%2010.3-3.4%2015.1-4-.8-7.4-3.1-11.4-4-10.1%2029.1-32%2055.1-60%2068.6a63.4%2063.4%200%200%201-41.6%205.5c-1.8%200-2.6-2.7-1.7-4a96.3%2096.3%200%200%200%2014-42.2%20128.8%20128.8%200%200%200-22.1-79.2c-7.3-10-16-19.3-24.5-28.5-3.8-4.2-7.2-8.8-10.7-13.3%203%2012.9%207.8%2025.4%2014.1%2037%20.6%201.2%201.5%202.5%201.1%204-1%201.6-2.6%202.1-4.4%202.6-4.4%201.1-9.2%201.4-13.8%202.2-34.6%203.8-70.1%208.7-105%2011-3.8-1.8-7.1-5.8-10-8.8a153.2%20153.2%200%200%201-27.7-48.3c-1.6-4.4-3.2-8.9-4-13.6-.6%208%201%2015.2%202.7%2022.9%203.7%2015%209.4%2029.6%2016.9%2043.1l2.4%205c-1%20.8-2%201.4-3.3%201.5-7.1.9-14%20.4-21%20.6a73.8%2073.8%200%200%201-21.1-28c-11.3-24.5-14.1-51.1-11.3-77.7a128.9%20128.9%200%200%200-14%2066.5c1%2011.8%203.8%2024.8%2010.8%2034.6%201.4%202.3%204.3%204.2%203.4%207.2-1.1%202.5-4.5%202.9-6.8%203.2-7.7.6-15.4%201-23%202-21.1%201.3-41.8%204.8-63%205.5-8.2%201.1-16.3.5-24.5%201-1.8%2012-2.5%2024.3-1.5%2036.5%201%2019.2%204%2038.5%209.1%2057%20.6%202.4%202.3%204.6%202.7%207-.3%202.8-3.6%203.4-5.3%201.4a107%20107%200%200%201-17.4-24.5c-7-14.2-10.4-30.3-11.8-46-.8-14%20.3-28.6%206-41.7.6-1.4.6-1.9%200-3.4a102.8%20102.8%200%200%201-.6-73%20150.7%20150.7%200%200%201%2051.3-66.9c36.8-28.2%2083-43.4%20129-47%2017.8-2%2036-1.2%2054-1.7%208.4-.7%2016.7-1.4%2025-1.8%2012-1.3%2023.9-2%2036-1.6Z%22%2F%3E%3Cpath%20d%3D%22M719.1%20518.1c.7-.5%201.7-.7%203-.4l.6.6c.6%203.5-.6%207.9-3%2010.4-2%201.6-4.9-.3-4-2.7%201-2.6%201.8-5.5%203.4-7.9ZM719.1%20576.3c1.9-.4%204%20.6%205.8%201%205.9%201.4%2012%201.9%2018.1%201.2%202.3-.3%204.8%201%204.8%203.5-.9%203-2.3%205.8-2.8%209a47%2047%200%200%200%204.7%2029.3%2067.1%2067.1%200%200%200%2031.4%2030.6c2.6%201.3%206%202.1%208%204.1%201%202.3-1%204-3%204.2-15.3%202.3-30.6%205.3-46.1%204.9a69.4%2069.4%200%200%201-35.8-9.5c-4.4%207.4-8.1%2015.6-13%2022.5-1.2%201.8-3.1%202.7-5.2%202-2.6-.9-5-2.4-7.4-3.7-8.7-5-17.3-10.5-25.1-16.9-1.5-1.4-4.1-3.3-4.3-5.6-.2-2.7%203-3.7%204.7-5a227.5%20227.5%200%200%200%2062.9-69.1c.6-1%201-2.3%202.3-2.5ZM364.5%20614.5c8.1%209.3%2017.2%2017.5%2026.7%2025.3%203.5%202.9%207.5%205%2010.9%208%201.7%201.3%201.8%204-.1%205.1a65%2065%200%200%201-33%209.7c-9.5.3-19%20.5-28.5-.5-3%200-4.1-3.7-1.6-5.3%204-2.6%207.6-5.6%2010.4-9.5%205-7.1%208.7-15.8%2010.3-24.3.3-2.5.1-5.2.7-7.7.8-1.5%203-2.5%204.2-.8Z%22%2F%3E%3C%2Fg%3E%3Cpath%20d%3D%22M617%20244.4a191%20191%200%200%201%2080%2032.7c13%209.6%2025.1%2021.1%2034.5%2034.4a200.4%20200.4%200%200%201%2019.9%2033.3%20191%20191%200%200%201%2018%2063.2c.7%2011%201.5%2022.2-.3%2033-.6%205.6-1%2010.9-2%2016.4l-5.5-2.4c.6-3.1%202-6.8%201.4-10-1-2.7-4.7-2.2-5.4.4a114%20114%200%200%201-57.8%2077.4%2060.6%2060.6%200%200%201-36.4%207.4c5-9.7%209.2-19.5%2011.5-30.2%201.6-9.6%202.5-19.2%201.4-29a156.2%20156.2%200%200%200-6.4-30.9c-4-12-10-23.5-17-34-7.3-10.2-16-19.4-24.4-28.6-6.6-7.7-13.4-15.9-18-25-3-5-2.9-11.7-3.2-17.5.5-8.3%201-16.7%202.4-25%20.2-1.3-.5-2.6-.9-3.8-1.6%200-3.6-.7-4.5%201-1.1%202.4-1%205.4-1.4%208a114%20114%200%200%200%20.2%2037.7c1.4%208.6%204.1%2017.2%206.7%2025.6a166%20166%200%200%200%2011.5%2027.5c-7.3%201.4-14.5%202-21.8%203-21.7%202.3-43.7%205.3-65.5%207.3-7.6%201.1-15.4%201.1-23%202.2a38%2038%200%200%201-5.5.2L503%20416a145.1%20145.1%200%200%201-37.3-78.7c-.4-1.8-.2-4-2.3-4.7-2.1-1-3.6%201.1-4.3%202.8a69.7%2069.7%200%200%200-2%2025.7c2.3%2021.3%209.5%2041.4%2019.4%2060.3-3.9.5-7.8.7-11.6.4-2.3-.2-3.7-2-5.2-3.5a88.3%2088.3%200%200%201-19-33%20141%20141%200%200%201-5.3-68.2%2078.6%2078.6%200%200%201%2016.5-38c1.6-1.9%204.3-3.6%204.9-6-.3-3-3-4.1-5.2-2.2-9%207.5-15%2019.1-18.4%2030.2-.8%203.7-3.2%205.9-5.2%209a133.8%20133.8%200%200%200-18.8%2054c-.4%207.3-1.5%2014.8-.7%2022a78.1%2078.1%200%200%200%2011.7%2040.2v.6c-8.6%201.2-17.2%201.5-25.8%202.4-5.2.9-10.4.7-15.5%201.4-7%201-14%201.4-20.9%202.4-10.2.5-20.5%202.2-30.7%202-2-6-3.8-12-4.7-18.2-2.8-21.9.4-44.2%208.7-64.6a110.1%20110.1%200%200%201%2038.4-50.5c2-1.2%201.8-4.7-.7-5.2-2.7-.5-4.1%201.2-6%202.5a111.3%20111.3%200%200%200-33%2041.1%20144%20144%200%200%200-14.7%2060.9c0%2011.8%202%2023.3%205.5%2034.6-5.8.4-11.6.3-17.4.2-8-15.4-12-32.5-11.2-49.8.8-8.5%202-16.9%204.6-25a135.7%20135.7%200%200%201%2039.4-58.7c11.3-10.4%2024-19%2037.4-26.5%2030-16.4%2063.3-25.8%2097.3-28.7%209.4-1.8%2018.6-1%2028-1.3%209.7-.2%2019.4%200%2029-.7%2011.4-.6%2022.6-1.7%2034-2.5%2018.3-2%2037-1.4%2055%201.8ZM297%20436.8c.7%201.3%201.5%202.6%202.4%203.8%201.9%201.3%203.8%201%206%201-2.3%2014.3-1.8%2029-1%2043.4%201%2013%203%2025.9%205.7%2038.6-1%200-1.7-.4-2.2-1.5-4.9-7.7-8.1-16.6-10.5-25.3a128.3%20128.3%200%200%201-4.3-33.8c-.2-9%201-17.7%203.9-26.2ZM721.8%20582.5a83.5%2083.5%200%200%200%2018.6%201.8c-4%2013-2%2027%204.2%2039.1A71.4%2071.4%200%200%200%20766%20649c3%202.4%206.3%203.9%209.1%206.3-10.6%201.8-21.3%203-32.1%202.8a60%2060%200%200%201-37.1-9.8c-1.7-.9-3.6-.6-4.7%201-5.2%207.6-8.8%2016.1-14.1%2023.7-5.5-2-10.4-5.7-15.3-8.7-5-3.4-10.6-6.7-14.7-11.1a223%20223%200%200%200%2030-25.9%20220%20220%200%200%200%2034.7-44.7ZM365.6%20624a278%20278%200%200%200%2021.5%2020.1c2.4%202.2%205.1%203.4%207%206-13%207.6-31.4%207.4-46%207.2%202-2.5%204.3-4.5%206.1-7%205-6.9%208.1-14.5%2010.5-22.5l.2-.8.8-3Z%22%20fill%3D%22%23dba3be%22%2F%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(-161%20-83)%22%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fsvg%3E)
%20by%20%E2%80%9EPablo%20Stanley%E2%80%9D%2C%20licensed%20under%20%E2%80%9EFree%20for%20personal%20and%20commercial%20use%E2%80%9D%20(https%3A%2F%2Fbottts.com%2F)%3C%2Fdc%3Arights%3E%3C%2Frdf%3ADescription%3E%3C%2Frdf%3ARDF%3E%3C%2Fmetadata%3E%3Cmask%20id%3D%22viewboxMask%22%3E%3Crect%20width%3D%22180%22%20height%3D%22180%22%20rx%3D%220%22%20ry%3D%220%22%20x%3D%220%22%20y%3D%220%22%20fill%3D%22%23fff%22%20%2F%3E%3C%2Fmask%3E%3Cg%20mask%3D%22url(%23viewboxMask)%22%3E%3Crect%20fill%3D%22%23c0aede%22%20width%3D%22180%22%20height%3D%22180%22%20x%3D%220%22%20y%3D%220%22%20%2F%3E%3Cg%20transform%3D%22translate(0%2066)%22%3E%3Cg%20opacity%3D%22.9%22%20stroke%3D%22%232A3544%22%3E%3Cellipse%20cx%3D%2232.5%22%20cy%3D%2223%22%20rx%3D%2216.5%22%20ry%3D%2218%22%20stroke-width%3D%226%22%2F%3E%3Cpath%20d%3D%22M29.51%2036.76c-7.4%204.29-17%201.55-21.42-6.1%22%20stroke-width%3D%224%22%2F%3E%3Cellipse%20cx%3D%2228.5%22%20cy%3D%2252.5%22%20rx%3D%2216.5%22%20ry%3D%2214.5%22%20stroke-width%3D%224%22%2F%3E%3C%2Fg%3E%3Cg%20opacity%3D%22.9%22%20stroke%3D%22%232A3544%22%3E%3Cpath%20d%3D%22M168.6%2060.42c-4.27-7.41-13.95-9.84-21.6-5.42%22%20stroke-width%3D%224%22%2F%3E%3Cellipse%20cx%3D%22148.5%22%20cy%3D%2222.5%22%20rx%3D%2216.5%22%20ry%3D%2215.5%22%20stroke-width%3D%226%22%2F%3E%3C%2Fg%3E%3Cmask%20id%3D%22sidesCables02-a%22%20style%3D%22mask-type%3Aluminance%22%20maskUnits%3D%22userSpaceOnUse%22%20x%3D%2221%22%20y%3D%220%22%20width%3D%22138%22%20height%3D%2272%22%3E%3Cg%20fill%3D%22%23fff%22%3E%3Crect%20x%3D%2221%22%20y%3D%2227%22%20width%3D%2216%22%20height%3D%2222%22%20rx%3D%222%22%2F%3E%3Crect%20x%3D%2222%22%20y%3D%2260%22%20width%3D%2216%22%20height%3D%2212%22%20rx%3D%222%22%2F%3E%3Crect%20x%3D%22143%22%20y%3D%2242%22%20width%3D%2216%22%20height%3D%2222%22%20rx%3D%222%22%2F%3E%3Crect%20x%3D%22143%22%20width%3D%2216%22%20height%3D%2222%22%20rx%3D%222%22%2F%3E%3C%2Fg%3E%3C%2Fmask%3E%3Cg%20mask%3D%22url(%23sidesCables02-a)%22%3E%3Cpath%20d%3D%22M0%200h180v76H0V0Z%22%20fill%3D%22%23fb8c00%22%2F%3E%3Cpath%20d%3D%22M0%200h180v76H0V0Z%22%20fill%3D%22%23fff%22%20fill-opacity%3D%22.3%22%2F%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(41)%22%3E%3Cmask%20id%3D%22topHorns-a%22%20style%3D%22mask-type%3Aluminance%22%20maskUnits%3D%22userSpaceOnUse%22%20x%3D%228%22%20y%3D%2212%22%20width%3D%2284%22%20height%3D%2240%22%3E%3Cg%20fill%3D%22%23fff%22%3E%3Cpath%20d%3D%22M8%2040h26v12H8z%22%2F%3E%3Cpath%20transform%3D%22matrix(-1%200%200%201%2092%2040)%22%20d%3D%22M0%200h26v12H0z%22%2F%3E%3Cpath%20fill-rule%3D%22evenodd%22%20clip-rule%3D%22evenodd%22%20d%3D%22M16.52%2013.74c0%207.84%205.39%2020.71%2013.72%2027.04H11.36S7.84%2022.66%2013.43%2014.1c.9-1.38%203.1-1.42%203.1-.36ZM84%2014c.66%207.04-5.77%2020.62-14%2027h19s3.14-18.26-2-27c-1-1.7-3.14-1.45-3%200Z%22%2F%3E%3C%2Fg%3E%3C%2Fmask%3E%3Cg%20mask%3D%22url(%23topHorns-a)%22%3E%3Cpath%20d%3D%22M0%200h100v52H0V0Z%22%20fill%3D%22%23fb8c00%22%2F%3E%3Cpath%20d%3D%22M0%200h100v52H0V0Z%22%20fill%3D%22%23fff%22%20fill-opacity%3D%22.3%22%2F%3E%3Cpath%20fill%3D%22%23000%22%20fill-opacity%3D%22.4%22%20d%3D%22M0%2040h100v12H0z%22%2F%3E%3Cpath%20fill-rule%3D%22evenodd%22%20clip-rule%3D%22evenodd%22%20d%3D%22M15.46%2013h16.1v27H20.83c-7.45-7.85-5.36-27-5.36-27ZM84.82%2013h7.75v27H81.82c5.75-7.8%203-27%203-27Z%22%20fill%3D%22%23fff%22%20fill-opacity%3D%22.4%22%2F%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(25%2044)%22%3E%3Cmask%20id%3D%22faceSquare04-a%22%20style%3D%22mask-type%3Aluminance%22%20maskUnits%3D%22userSpaceOnUse%22%20x%3D%220%22%20y%3D%220%22%20width%3D%22130%22%20height%3D%22120%22%3E%3Cpath%20fill-rule%3D%22evenodd%22%20clip-rule%3D%22evenodd%22%20d%3D%22M0%20102V68.85a40%2040%200%200%201%202.28-13.31L19.76%2012A18%2018%200%200%201%2036.74%200h56.52a18%2018%200%200%201%2016.98%2012l17.48%2043.54A40%2040%200%200%201%20130%2068.85V102a18%2018%200%200%201-18%2018H18a18%2018%200%200%201-18-18Z%22%20fill%3D%22%23fff%22%2F%3E%3C%2Fmask%3E%3Cg%20mask%3D%22url(%23faceSquare04-a)%22%3E%3Cpath%20d%3D%22M-2-2h134v124H-2V-2Z%22%20fill%3D%22%23fb8c00%22%2F%3E%3Cg%20transform%3D%22translate(-1%20-1)%22%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(52%20124)%22%3E%3Crect%20x%3D%224%22%20y%3D%225%22%20width%3D%2268%22%20height%3D%2222%22%20rx%3D%225%22%20fill%3D%22%23000%22%20fill-opacity%3D%22.2%22%2F%3E%3Crect%20x%3D%228%22%20y%3D%229%22%20width%3D%2260%22%20height%3D%2214%22%20rx%3D%222%22%20fill%3D%22%23fff%22%2F%3E%3Cpath%20fill%3D%22%23000%22%20fill-opacity%3D%22.1%22%20d%3D%22M18%209h4v14h-4zM42%209h4v14h-4zM30%209h4v14h-4zM54%209h4v14h-4z%22%2F%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(38%2076)%22%3E%3Cpath%20d%3D%22m18%2019%2012-2M20%2031c0-3.31%202.9-6%207-6%203.1%200%206%202.69%206%206M86%2020l-12-3M84%2031c0-3.31-2.9-6-6-6-4.1%200-7%202.69-7%206%22%20stroke%3D%22%23000%22%20stroke-width%3D%224%22%20stroke-linecap%3D%22round%22%20stroke-linejoin%3D%22round%22%2F%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fsvg%3E)