在当今数据驱动的世界中,选择合适的编程语言来进行数据分析可谓至关重要。Python,这一语言近年来已成为数据分析领域的佼佼者。许多企业和开发者都不约而同地选择了Python作为他们的主要数据分析工具。这一现象背后有着深刻的原因:Python不仅仅是一门编程语言,它更是一个强大的生态系统,支持无数的开源工具和库,使得数据分析更加高效和便捷。

Python之所以在数据分析领域占据主导地位,不仅仅因为它易于学习和使用,更因为其拥有众多强大的库和工具,这些工具可以处理几乎所有的数据分析任务。从数据清洗、数据可视化到机器学习,Python都能提供相应的解决方案。此外,Python的开源社区活跃,开发者可以轻松找到所需的工具,并且这些工具通常由世界各地的专家不断更新和优化。这种社区支持使得Python在处理复杂的数据分析任务时显得尤为可靠。
当然,选择Python进行数据分析并不意味着就此止步,如何有效利用Python生态中的开源工具来提升工作效率也是一个值得深思的问题。对于任何一个希望利用数据分析推动业务发展的企业来说,FineBI这样的商业智能工具可以提供强大的支持。FineBI连续八年在中国市场占有率第一,证明了其在帮助企业实现数据分析目标方面的成功。
🐍 Python为何成为数据分析的首选?
Python以其简单的语法和强大的功能成为数据分析的首选,这不是偶然。它的设计理念和广泛的应用领域使得它在数据分析中独具优势。
1. Python的简单易用性
Python因其清晰的语法结构和易读性而闻名。即使是数据分析的新手,也可以快速上手进行数据处理。Python的语法接近自然语言,使得编写代码变得更加直观和高效。
- 清晰的语法结构:Python的代码风格强调可读性,减少了编程中的复杂性。
- 广泛的文档支持:Python社区提供了大量的文档和教程,帮助用户解决可能遇到的各种问题。
- 丰富的学习资源:无论是初学者还是专家,Python都有丰富的学习资源可供选择。
表格化信息(Python的特点):
| 特点 | 描述 | 优势 |
|---|---|---|
| 易读性 | 代码风格接近自然语言 | 降低学习门槛,提升开发效率 |
| 庞大的社区支持 | 提供丰富的文档和教程 | 快速解决问题,获取最新技术动态 |
| 多平台兼容性 | 兼容Windows、MacOS、Linux等多种操作系统 | 灵活性强,适应多种开发环境 |
2. 强大的库和工具支持
Python之所以在数据分析领域占据主导地位,离不开它强大的库和工具支持。无论是数据处理、可视化还是机器学习,Python都有相应的库来满足需求。
- NumPy和Pandas:这两个库是数据处理和分析的基础。NumPy提供了强大的数组对象,Pandas则提供了数据帧对象,支持灵活的数据操作。
- Matplotlib和Seaborn:用于数据可视化的库,帮助分析人员创建各种图表,从而更直观地理解数据。
- Scikit-learn:机器学习库,提供了一系列工具用于数据建模和预测。
表格化信息(Python的库):
| 库名 | 功能描述 | 应用场景 |
|---|---|---|
| NumPy | 数值计算和数组处理 | 数据预处理,科学计算 |
| Pandas | 数据操作和分析 | 数据清洗,数据分析 |
| Matplotlib | 数据可视化 | 图表创建,数据呈现 |
| Seaborn | 高级数据可视化 | 热图,分类图等复杂图表 |
| Scikit-learn | 机器学习模型 | 数据建模,预测分析 |
3. 跨平台和开源社区支持
Python不仅具备跨平台特性,还拥有一个活跃的开源社区。这意味着用户可以在不同的操作系统上轻松使用Python,同时也可以利用社区提供的开源资源来解决问题。
- 跨平台特性:Python代码可以在Windows、MacOS和Linux上运行,确保灵活性和兼容性。
- 活跃的开源社区:Python的开源社区不断开发和维护新的库和工具,并为用户提供支持和帮助。
- 开源资源的丰富性:用户可以访问大量的开源项目和代码库,快速找到问题的解决方案。
🚀 开源工具如何助力高效工作?
开源工具是提升工作效率的关键所在,它们为开发者和数据分析师提供了灵活且强大的解决方案。
1. 数据处理与分析的开源工具
在数据分析过程中,数据处理是一个关键步骤。Python提供了多种开源工具来帮助处理和分析数据。
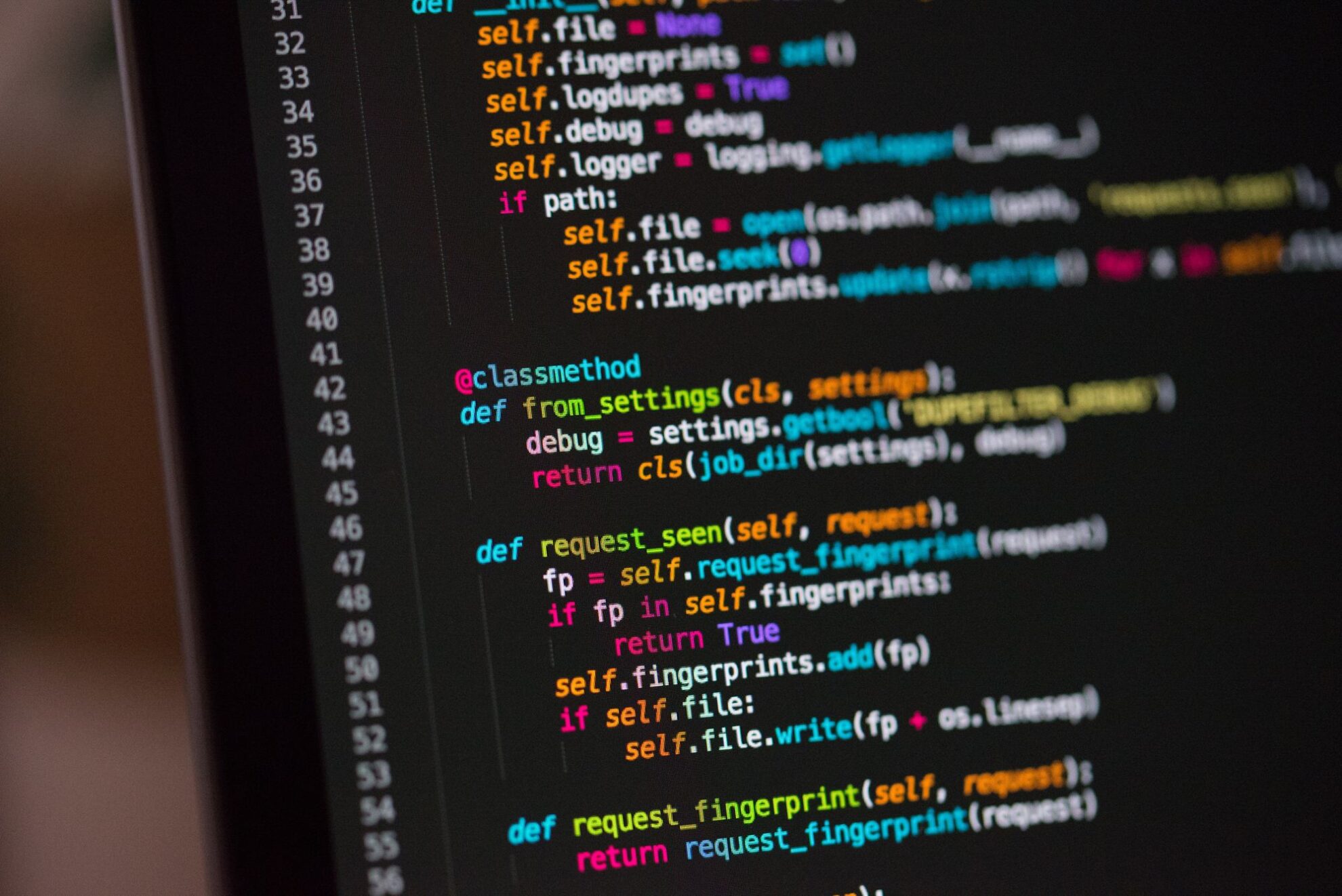
- Pandas:作为数据处理的核心库,Pandas提供了强大的数据帧操作能力,支持数据清洗、变换和聚合。
- Dask:用于并行和分布式计算的库,能够处理大规模数据集。
- PySpark:基于Apache Spark的Python API,支持大数据处理和分析。
表格化信息(数据处理工具):
| 工具名 | 功能描述 | 优势 |
|---|---|---|
| Pandas | 数据帧操作和分析 | 方便数据清洗和变换,支持复杂数据操作 |
| Dask | 并行和分布式计算 | 处理大规模数据,支持多核计算 |
| PySpark | 大数据处理和分析 | 适用于大数据集,支持实时数据分析 |
2. 数据可视化与呈现工具
数据可视化是数据分析的重要组成部分,Python的开源工具可以帮助快速创建可视化图表。
- Matplotlib:经典的可视化库,支持创建各种基本图表。
- Seaborn:基于Matplotlib,提供更高级的可视化功能和图表样式。
- Plotly:支持交互式图表创建,适用于动态数据展示。
表格化信息(可视化工具):
| 工具名 | 功能描述 | 优势 |
|---|---|---|
| Matplotlib | 基础图表创建 | 支持多种图表类型,易于使用 |
| Seaborn | 高级图表创建 | 提供附加样式和高级功能,适合复杂数据可视化 |
| Plotly | 交互式图表创建 | 支持动态和交互式图表,适合实时数据展示 |
3. 机器学习与预测分析工具
Python的开源工具在机器学习领域也表现出色,提供了强大的预测分析能力。
- Scikit-learn:包含多种机器学习算法,支持分类、回归和聚类分析。
- TensorFlow和Keras:深度学习框架,适用于复杂的神经网络模型构建。
- XGBoost:高效的梯度提升库,广泛用于比赛和实践中的机器学习任务。
表格化信息(机器学习工具):

| 工具名 | 功能描述 | 优势 |
|---|---|---|
| Scikit-learn | 基础机器学习算法 | 简单易用,支持多种机器学习任务 |
| TensorFlow | 深度学习框架 | 适合复杂模型构建,支持大规模数据训练 |
| XGBoost | 高效梯度提升库 | 性能优异,适合比赛和实践中的机器学习任务 |
📚 结论与推荐
综上所述,Python凭借其简单易用性、强大的库支持以及活跃的开源社区,成为数据分析的首选语言。开源工具的丰富性进一步助力高效数据工作,使得Python在数据处理、可视化和机器学习领域几乎无所不能。企业在利用数据分析工具推动业务发展时,FineBI这样的商业智能工具可以提供强大的支持,帮助企业实现数据分析目标。选择正确的工具和语言,将是企业在数据分析中取得成功的关键。
参考文献:
- 《Python数据科学手册》,Jake VanderPlas著。
- 《Python机器学习》,Sebastian Raschka & Vahid Mirjalili著。
- 《深入浅出数据分析》,张志斌著。
通过合理利用Python及其开源工具,企业和个人可以大幅提高数据分析的效率,从而更好地驱动业务决策并实现价值最大化。
本文相关FAQs
🤔 为什么那么多数据科学家选择Python进行数据分析?
最近老板一直在问我们为什么不选用其他语言进行数据分析,非要用Python。市面上明明有那么多选择,比如R、Matlab等,还有不少商业软件,Python到底好在哪里呢?有没有大佬能分享一下Python在数据分析方面的优势,帮我理清思路?
Python之所以在数据科学领域大受欢迎,主要得益于其易学易用、功能强大以及社区活跃。对于很多刚接触编程的人来说,Python的语法简单直观,不需要面对过于复杂的语法规则,这无疑降低了入门门槛。Python的丰富库也是一大优势,像NumPy、Pandas、Matplotlib、Scikit-learn等都是数据分析的强力工具,涵盖数据处理、可视化、机器学习等多个领域。
这种生态的丰富性让Python在数据分析的每个环节都能找到合适的工具,极大提升了工作效率。除了技术层面的原因,Python的广泛使用也与其在其他领域的应用密不可分。比如在Web开发、自动化运维、人工智能等领域,Python同样表现出色,这种跨领域的应用使得Python拥有一个庞大且活跃的开发者社区,遇到问题时总能在网络上找到解决方案。
不仅如此,Python还是一种开源语言,这意味着企业和个人不需要支付高昂的许可证费用就能使用它。这对预算有限的团队尤其重要。相比于一些商业软件,Python的开源特性不仅降低了成本,还为用户提供了更大的灵活性。
总而言之,Python能在数据分析领域占据一席之地,主要在于其简单易学、功能全面、社区强大和开源免费的综合优势。
🛠️ 开源工具如何助力提升数据分析效率?
在各种开源工具层出不穷的今天,我们的数据分析工作该如何高效开展?有没有哪些工具是大家公认好用的?特别是能提升团队协作和数据可视化效果的,跪求推荐!
开源工具的崛起为数据分析领域带来了巨大的变革,尤其在提升效率和降低成本方面。一个好的开源工具不仅能提高个人的工作效率,还能在团队协作中发挥重要作用。Jupyter Notebook是数据分析师们常用的工具之一。它支持Python、R等多种语言,可以将代码、图表和文本整合在一起,便于记录分析过程和结果,且非常适合团队分享和协作。
另一个值得推荐的工具是Apache Superset,它提供了丰富的可视化选项,不仅支持多种图表,还可以轻松创建复杂的仪表盘。对于需要频繁展示数据分析结果的团队来说,这是一个非常便捷的选择。此外,Superset的开源特性使得用户可以根据自己的需求进行定制和扩展。
在数据存储和处理方面,Apache Hadoop和Apache Spark都是非常成熟的生态系统。它们能处理大规模的数据集,是进行大数据分析的理想选择。特别是Spark,它支持内存中计算,大大提升了数据处理速度。
除了这些工具,FineBI也是不可忽视的选择,它不仅支持自助分析,还能与办公应用无缝集成,帮助企业打造一体化的数据分析平台。对于有更高协作需求的企业来说, FineBI在线试用 是个不错的起点。
通过合理选择和组合这些工具,团队可以在数据分析的不同阶段实现效率的提升,从而更快速地获取数据洞察。
🔄 如何从零开始打造高效的数据分析工作流?
想要从零开始打造一套数据分析工作流,有哪些关键步骤和工具需要注意?尤其是对于我们这种数据基础薄弱的小团队,有没有一些实用的建议和经验分享?
打造一套高效的数据分析工作流对于任何团队来说都是一个挑战,尤其是对于数据基础薄弱的小团队。首先需要明确的是,数据分析工作流的核心在于数据的收集、清洗、分析、可视化和分享这几个环节。以下是一些实用的步骤和工具建议:
- 数据收集:使用工具如Scrapy进行网络爬虫数据的自动采集,或者通过API接口获取数据。对于企业内部数据,常常需要从数据库中提取,这时可以使用SQL工具进行数据提取。
- 数据清洗:清洗是保证数据质量的关键步骤。Pandas是Python中非常强大的数据处理库,可以用于数据清洗和转换。它提供了丰富的函数来处理缺失值、重复数据和数据格式化。
- 数据分析:在分析阶段,可以结合使用NumPy和SciPy进行数据的统计分析和科学计算。对于机器学习模型,可以使用Scikit-learn进行建模和预测。
- 数据可视化:可视化是将分析结果直观展示的关键。Matplotlib和Seaborn是Python中非常常用的可视化库,可以生成各种类型的图表。对于更复杂的交互式可视化,可以使用Plotly。
- 结果分享:使用Jupyter Notebook记录分析过程,便于分享和协作。对于企业内部分享,考虑使用像FineBI这样的商业智能工具,它不仅能创建详尽的报告,还支持多人协作和数据故事的编写。
通过以上步骤,团队可以逐步建立起一套完整的工作流体系。在工具选择上,建议根据团队实际情况进行取舍,确保工具的使用能真正提升效率和协作能力。不妨先从简单的工具和流程开始,随着团队能力的提升再进行优化和扩展。这样既能快速见效,也能在实践中不断积累经验。
%20by%20%E2%80%9EPablo%20Stanley%E2%80%9D%2C%20licensed%20under%20%E2%80%9EFree%20for%20personal%20and%20commercial%20use%E2%80%9D%20(https%3A%2F%2Fbottts.com%2F)%3C%2Fdc%3Arights%3E%3C%2Frdf%3ADescription%3E%3C%2Frdf%3ARDF%3E%3C%2Fmetadata%3E%3Cmask%20id%3D%22viewboxMask%22%3E%3Crect%20width%3D%22180%22%20height%3D%22180%22%20rx%3D%220%22%20ry%3D%220%22%20x%3D%220%22%20y%3D%220%22%20fill%3D%22%23fff%22%20%2F%3E%3C%2Fmask%3E%3Cg%20mask%3D%22url(%23viewboxMask)%22%3E%3Crect%20fill%3D%22%23ffdfbf%22%20width%3D%22180%22%20height%3D%22180%22%20x%3D%220%22%20y%3D%220%22%20%2F%3E%3Cg%20transform%3D%22translate(0%2066)%22%3E%3Cpath%20d%3D%22M38%2012c-2.95%2011.7-19.9%206.67-23.37%2018-3.46%2011.35%208.03%2020%2017.53%2020%22%20stroke%3D%22%232A3544%22%20stroke-width%3D%226%22%20opacity%3D%22.9%22%2F%3E%3Cpath%20d%3D%22M150%2055c8.4%203.49%2020.1-7.6%2016-16.5-4.1-8.9-16-6.7-16-19.3%22%20stroke%3D%22%232A3544%22%20stroke-width%3D%224%22%20opacity%3D%22.9%22%2F%3E%3Cmask%20id%3D%22sidesCables01-a%22%20style%3D%22mask-type%3Aluminance%22%20maskUnits%3D%22userSpaceOnUse%22%20x%3D%2221%22%20y%3D%226%22%20width%3D%22138%22%20height%3D%2258%22%3E%3Cg%20fill%3D%22%23fff%22%3E%3Crect%20x%3D%2221%22%20y%3D%2235%22%20width%3D%2216%22%20height%3D%2222%22%20rx%3D%222%22%2F%3E%3Crect%20x%3D%22136%22%20y%3D%2242%22%20width%3D%2223%22%20height%3D%2222%22%20rx%3D%222%22%2F%3E%3Crect%20x%3D%22136%22%20y%3D%226%22%20width%3D%2223%22%20height%3D%2218%22%20rx%3D%222%22%2F%3E%3C%2Fg%3E%3C%2Fmask%3E%3Cg%20mask%3D%22url(%23sidesCables01-a)%22%3E%3Cpath%20d%3D%22M0%200h180v76H0V0Z%22%20fill%3D%22%231e88e5%22%2F%3E%3Cpath%20d%3D%22M0%200h180v76H0V0Z%22%20fill%3D%22%23fff%22%20fill-opacity%3D%22.3%22%2F%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(41)%22%3E%3Cmask%20id%3D%22topHorns-a%22%20style%3D%22mask-type%3Aluminance%22%20maskUnits%3D%22userSpaceOnUse%22%20x%3D%228%22%20y%3D%2212%22%20width%3D%2284%22%20height%3D%2240%22%3E%3Cg%20fill%3D%22%23fff%22%3E%3Cpath%20d%3D%22M8%2040h26v12H8z%22%2F%3E%3Cpath%20transform%3D%22matrix(-1%200%200%201%2092%2040)%22%20d%3D%22M0%200h26v12H0z%22%2F%3E%3Cpath%20fill-rule%3D%22evenodd%22%20clip-rule%3D%22evenodd%22%20d%3D%22M16.52%2013.74c0%207.84%205.39%2020.71%2013.72%2027.04H11.36S7.84%2022.66%2013.43%2014.1c.9-1.38%203.1-1.42%203.1-.36ZM84%2014c.66%207.04-5.77%2020.62-14%2027h19s3.14-18.26-2-27c-1-1.7-3.14-1.45-3%200Z%22%2F%3E%3C%2Fg%3E%3C%2Fmask%3E%3Cg%20mask%3D%22url(%23topHorns-a)%22%3E%3Cpath%20d%3D%22M0%200h100v52H0V0Z%22%20fill%3D%22%231e88e5%22%2F%3E%3Cpath%20d%3D%22M0%200h100v52H0V0Z%22%20fill%3D%22%23fff%22%20fill-opacity%3D%22.3%22%2F%3E%3Cpath%20fill%3D%22%23000%22%20fill-opacity%3D%22.4%22%20d%3D%22M0%2040h100v12H0z%22%2F%3E%3Cpath%20fill-rule%3D%22evenodd%22%20clip-rule%3D%22evenodd%22%20d%3D%22M15.46%2013h16.1v27H20.83c-7.45-7.85-5.36-27-5.36-27ZM84.82%2013h7.75v27H81.82c5.75-7.8%203-27%203-27Z%22%20fill%3D%22%23fff%22%20fill-opacity%3D%22.4%22%2F%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(25%2044)%22%3E%3Cmask%20id%3D%22faceSquare02-a%22%20style%3D%22mask-type%3Aluminance%22%20maskUnits%3D%22userSpaceOnUse%22%20x%3D%220%22%20y%3D%220%22%20width%3D%22130%22%20height%3D%22120%22%3E%3Cpath%20d%3D%22M0%2012A12%2012%200%200%201%2012%200h106a12%2012%200%200%201%2012%2012v70a38%2038%200%200%201-38%2038H38A38%2038%200%200%201%200%2082V12Z%22%20fill%3D%22%23fff%22%2F%3E%3C%2Fmask%3E%3Cg%20mask%3D%22url(%23faceSquare02-a)%22%3E%3Cpath%20d%3D%22M-2-2h134v124H-2V-2Z%22%20fill%3D%22%231e88e5%22%2F%3E%3Cg%20transform%3D%22translate(-1%20-1)%22%3E%3Cpath%20d%3D%22M29.47%2034.03c-.1%200-.19-.06-.26-.12-.08-.07-.14-.12-.13.14.01.5.67-.05.4-.02ZM9.33%2048.92s.2-.56.03-.74c-.17.17-.18.42-.03.74ZM7.5%2052c.06%200%20.57-.28.48-.43-.12-.18-.49.34-.49.42ZM22.9%2059.14c-.13-.11-.53-.45-.28-.5.14-.03.5.36.32.54v-.01h-.01l-.03-.03ZM26.33%20108.46c.13-.02.66-.36.34-.45-.21-.04-.6.5-.34.46ZM52.63%2096.34c-.05.05-.2.09-.34.12-.15.04-.26.07-.16.1.19.06.84.16.5-.22ZM4.76%2043.63ZM5.1%2071.63l.06-.1c1.02%200-.68.19-.07.1ZM80.53%20109.92c.09-.02.1-.02.1-.11-.07.01-.08.02-.1.1ZM29.17%20117.78c.08-.02.09-.03.1-.11-.08.01-.09.02-.1.1ZM9.01%2049.75c.08-.02.09-.03.1-.12-.08.02-.09.03-.1.12ZM65.84%2048.74c.02.09.03.1.1.1%200-.08-.01-.09-.1-.1ZM107.28%2076.91c-.08.02-.09.03-.1.12.08-.02.09-.03.1-.12Z%22%20fill%3D%22%23000%22%20fill-opacity%3D%22.2%22%2F%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(52%20124)%22%3E%3Crect%20x%3D%2216%22%20y%3D%228%22%20width%3D%2244%22%20height%3D%224%22%20rx%3D%222%22%20fill%3D%22%23000%22%20fill-opacity%3D%22.8%22%2F%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(38%2076)%22%3E%3Crect%20y%3D%2212%22%20width%3D%22104%22%20height%3D%2232%22%20rx%3D%2216%22%20fill%3D%22%23000%22%20fill-opacity%3D%22.8%22%2F%3E%3Crect%20x%3D%2224%22%20y%3D%2222%22%20width%3D%2210%22%20height%3D%2212%22%20rx%3D%222%22%20fill%3D%22%23F4F4F4%22%2F%3E%3Crect%20x%3D%2270%22%20y%3D%2222%22%20width%3D%2210%22%20height%3D%2212%22%20rx%3D%222%22%20fill%3D%22%23F4F4F4%22%2F%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fsvg%3E)
%20by%20%E2%80%9ELisa%20Wischofsky%E2%80%9D%2C%20licensed%20under%20%E2%80%9ECC0%201.0%E2%80%9D%20(https%3A%2F%2Fcreativecommons.org%2Fpublicdomain%2Fzero%2F1.0%2F)%3C%2Fdc%3Arights%3E%3C%2Frdf%3ADescription%3E%3C%2Frdf%3ARDF%3E%3C%2Fmetadata%3E%3Cmask%20id%3D%22viewboxMask%22%3E%3Crect%20width%3D%22980%22%20height%3D%22980%22%20rx%3D%220%22%20ry%3D%220%22%20x%3D%220%22%20y%3D%220%22%20fill%3D%22%23fff%22%20%2F%3E%3C%2Fmask%3E%3Cg%20mask%3D%22url(%23viewboxMask)%22%3E%3Crect%20fill%3D%22%23ffdfbf%22%20width%3D%22980%22%20height%3D%22980%22%20x%3D%220%22%20y%3D%220%22%20%2F%3E%3Cg%20transform%3D%22translate(10%20-60)%22%3E%3Cpath%20d%3D%22M580%20141c9%201%2019%204%2027%209%207%205%2015%209%2021%2015l19%2015c6%206%2010%2014%2013%2021s5%2014%204%2022c-1%205-3%209-6%2013-6%209-11%2018-19%2026%2014%208%2028%2017%2039%2029%2014%2018%2024%2039%2026%2062%201%2011%200%2023-3%2034-2%206-10%208-15%204-4-2-5-6-7-10s-5-7-6-11c-8-15-17-30-24-46l-7-14-24-1-12-1-8-5-11-8c-1%204-2%208-5%2011-1%203-4%203-7%202l-13-3-45-5c-28-1-57%202-86%206l-24%204-9-2-17-5c1%207%203%2015%203%2023-1%205%200%2010-3%2014-7%2014-15%2027-21%2042-7%2017-13%2035-17%2053%200%202-1%204-3%205l-12%202c5%209%205%2019%205%2029-1%2012-2%2026-9%2037%207%209%2010%2021%2010%2033%201%2018%200%2037-7%2054-2%205-5%2010-10%2012-1%201-4%202-4-1-2-5-2-11-3-16l-16-6-28-10-10-4c-3-2-5-6-7-9-10-20-17-41-21-63a296%20296%200%200%201%2017-150c-14%201-29%201-41-5-9-5-16-13-21-21-4-8-7-16-9-25v-21c2-13%207-26%2012-39l13-24c3-5%206-11%2010-15%207-9%2017-16%2026-22%2014-9%2028-17%2043-23%2013-6%2028-9%2042-6%2010%202%2019%206%2027%209%209%204%2017%2010%2023%2017%207%207%2011%2017%209%2027l-7%2022c11-2%2023-3%2035-2h19l51-1c-1-9%201-19%203-28%203-10%209-19%2017-25%2023-18%2054-26%2083-25Z%22%20fill%3D%22%23000000%22%2F%3E%3Cpath%20d%3D%22M495%20234c28%201%2056%206%2084%2015a201%20201%200%200%201%20100%2065c19%2025%2031%2055%2035%2086a361%20361%200%200%201%202%20101l-5%2034-4%2020c-1%202-1%202-3%202-2-4-2-8-2-12-1-15%201-29%202-44%201-24%203-48%201-72l-6-45c-7-28-20-54-40-75-18-18-40-33-63-43-22-9-44-15-67-19-18-3-36-4-54-4a277%20277%200%200%200-128%2029c-13%209-25%2020-35%2032a276%20276%200%200%200-55%20139c-1%2024%200%2047%208%2070l7%2015%2012%201%201%203c-3%202-7%202-11%203-10%202-20%206-29%2012-7%205-14%2011-18%2019-5%2010-3%2022-1%2033%205%2019%2017%2037%2033%2049%2011%209%2025%2014%2039%2016%2010%202%2020%200%2030-1%205%204%208%2012%2011%2017l18%2027a136%20136%200%200%200%2066%2050c22%209%2045%2014%2068%2019l41%208%2017%205v4h-12a535%20535%200%200%201-67-8%20255%20255%200%200%201-84-33c-11-7-21-16-29-27a214%20214%200%200%201-16%20123c-15%2027-40%2048-70%2057-3%201-7%202-10%201-2%200-2-1-2-3%201-3%204-5%206-6%2012-8%2026-14%2038-23%2013-11%2024-23%2031-38%206-15%2010-32%2012-49%202-13%203-26%202-40l-4-38-18-36-19%204a88%2088%200%200%201-75-38%2093%2093%200%200%201-20-58c0-9%203-18%208-25s12-13%2019-17c5-4%2012-6%2018-8l-9-24c-5-22-5-45-2-67a292%20292%200%200%201%2063-149c9-10%2018-19%2029-26%207-4%2014-5%2020-9%2043-19%2090-25%20137-22Z%22%20fill%3D%22%23000%22%2F%3E%3Cpath%20d%3D%22M475%20243a276%20276%200%200%201%20121%2023c23%2010%2045%2025%2063%2043%2020%2021%2033%2047%2040%2075l6%2045c2%2024%200%2048-1%2072-1%2015-3%2029-2%2044%200%204%200%208%202%2012l-1%2020c-2%205-2%2010-2%2016-2%2024-2%2049-6%2074-1%2012-3%2025-8%2036-3%209-8%2017-15%2024-12%2013-27%2024-43%2033-19%2011-39%2016-58%2024-5%202-10%204-13%208%208%201%2015%200%2023-2-5%2012-6%2024-6%2036%200%205-1%2011%201%2016%203%205%208%209%2013%2012l35%2013c22%208%2043%2018%2065%2027%202%204%205%207%206%2012%206%2011%207%2023%203%2035-5%2013-15%2024-27%2031-16%2011-36%2019-55%2024a494%20494%200%200%201-235-7c-20-7-40-14-58-24-14-8-29-18-40-31-6-8-11-19-12-29a122%20122%200%200%200%2086-107c4-24%204-49%200-73%208%2011%2018%2020%2029%2027l27%2014a331%20331%200%200%200%20124%2027h12v-4l-17-5-41-8c-23-5-46-10-68-19-13-6-27-13-39-21-10-9-19-18-27-29l-18-27c-3-5-6-13-11-17-10%201-20%203-30%201-14-2-28-7-39-16a94%2094%200%200%201-33-49c-2-11-4-23%201-33%204-8%2011-14%2018-19%209-6%2019-10%2029-12%204-1%208-1%2011-3l-1-3-12-1-7-15c-8-23-9-46-7-70a276%20276%200%200%201%2054-139c10-12%2022-23%2035-32a277%20277%200%200%201%20128-30Z%22%20fill%3D%22%23ffffff%22%2F%3E%3Cpath%20d%3D%22M260%20571c4%200%207%200%2011%202%205%201%2011%204%2014%208%202%203%202%207%200%2010-5%206-12%2010-16%2016%206%204%2014%206%2021%209%204%201%208%203%2011%206l1%203-8-2-24-7c-4-1-8-3-9-7-1-3%201-7%203-10l15-13c-4-7-15-8-19-15ZM703%20577l2%203%202%2016a483%20483%200%200%201-2%2089c-2%2011-5%2023-10%2033a198%20198%200%200%201-106%2071c-1%2014-3%2031-2%2047l5%205c8%206%2018%209%2027%2012a451%20451%200%200%201%2068%2028c7%204%2013%209%2018%2015-5%201-10-1-16-2-22-9-43-19-65-27l-35-13c-5-3-10-7-13-12-2-5-1-11-1-16%200-12%201-24%206-36-8%202-15%203-23%202%203-4%208-6%2013-8%2019-8%2039-13%2058-24%2016-9%2031-20%2043-33%207-7%2012-15%2015-24%205-11%207-24%208-36%204-25%204-50%206-74%200-6%200-11%202-16Z%22%20fill%3D%22%23000%22%2F%3E%3Cpath%20d%3D%22M683%20467c8%206%2011%2015%2012%2025%201%205%201%2012-2%2016-2%205-10%205-12%200-3-4-2-10-3-14-1-5-3-11-7-14-4-2-8-1-11%200%209%2013%209%2030%204%2045-2%206-5%2012-9%2017-4%203-8%206-12%207-4%202-10%201-14-2-5-5-7-11-7-17-1%204-2%209-6%2012-2-2-3-3-3-6-1-7%200-14%202-20%204-14%2011-26%2020-36%207-7%2015-13%2025-16%208-2%2016-1%2023%203ZM479%20473c18%207%2033%2021%2040%2040%203%207%205%2015%204%2022%200%202-1%205-3%204-3-2-5-6-6-9-5-9-10-17-17-25-8-9-18-16-29-19%206%2010%208%2022%208%2034-1%2011-5%2022-12%2030-5%206-12%2011-20%2010-6%200-11-1-15-5-9-7-13-17-15-28-1-8%200-15%202-22l-7%208c-3%204-10%204-13%200s-2-9%201-12c9-15%2024-27%2041-31%2013-3%2028-2%2041%203Z%22%20fill%3D%22%23000000%22%2F%3E%3Cpath%20d%3D%22M479%20386c16%201%2033%207%2046%2017%203%203%207%205%208%209%201%202-1%205-3%204-8-1-15-5-23-7-7-3-15-5-23-5-7-1-15%200-22%201-15%202-30%209-43%2016l-21%209-1-1c1-4%203-9%206-12%206-10%2017-16%2027-21%2015-7%2032-11%2049-10ZM673%20390c5%202%2011%205%2015%2010%204%204%205%209%204%2015l-23-7c-7-2-13-1-20-2-7%200-15%201-21%205l-13%208h-3c-1-3%200-6%202-8%205-9%2013-15%2022-18%2012-4%2024-6%2037-3Z%22%20fill%3D%22%23000000%22%2F%3E%3Cpath%20d%3D%22M609%20602c1%209-4%2016-9%2023-4%203-9%206-15%206s-13-3-19-5c-4-2-8-3-11-6l5-4c9-1%2017%203%2025%204%204%200%207-3%209-6%205-5%209-10%2015-12Z%22%20fill%3D%22%23000000%22%2F%3E%3Cpath%20d%3D%22M516%20651c18%205%2031%2016%2048%2021%207%203%2014%204%2021%202%2011-2%2021-8%2032-10%208-1%2017%201%2022%207%205%205%207%2012%207%2019%200%208-4%2016-9%2023a84%2084%200%200%201-53%2026l-26-1c-14-2-27-6-40-13-6-4-13-9-17-15l13%207c16%208%2033%2014%2051%2015%208%200%2017%200%2025-2%2010-2%2019-6%2027-12%206-4%2011-8%2015-14s6-15%203-22c-2-5-6-8-11-8-7-1-14%202-20%205l6%205c5%209%208%2021%206%2031-5-7-11-15-14-24-2-3-2-7-1-11-10%204-20%207-31%205l-1%2011-5%2025c-3-5-3-9-3-14%200-8%200-16%202-24-11-3-21-8-31-14-6%2013-15%2024-20%2036-3-5-1-11%201-16%203-9%207-17%2013-23-7-3-14-6-21-7s-14%202-18%207c-6%206-7%2015-4%2023%202%205%206%208%209%2012-5%201-9-2-12-5-6-7-9-17-6-26%202-9%2010-17%2020-20%207-2%2015-1%2022%201Z%22%20fill%3D%22%23000000%22%2F%3E%3Cpath%20d%3D%22M508%20220a271%20271%200%200%201%2097%2024c14%207%2029%2014%2042%2023%208%205%2016%2011%2022%2018l22%2025c-9%204-18%203-27%202-17-2-34-4-51-3l-8-1-7-5-12-8c0%204-1%207-3%2011-2%202-4%203-7%203-4-1-7-3-11-3a470%20470%200%200%200-155%203h-11l-18-6c1%209%204%2018%203%2026-1%204-1%208-3%2011-7%2014-15%2027-21%2042-7%2017-13%2035-17%2053%200%202-1%204-3%205l-12%202c5%209%206%2020%205%2030-1%2012-3%2026-9%2036%207%209%2010%2021%2010%2033%201%2019%200%2037-7%2055-2%204-5%209-10%2011-1%201-4%201-4-1-2-4-2-9-3-13-2-15-9-29-20-40-8-7-17-14-26-19-6-2-11-4-16-8l-6-8c-12-32-16-67-12-101a285%20285%200%200%201%2037-113c10-16%2022-30%2035-43%2010-9%2020-17%2031-23l14-5%2032-11%2019-2h43c23%200%2044-2%2067%200Z%22%20fill%3D%22%23000000%22%2F%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(10%20-60)%22%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fsvg%3E)
%20by%20%E2%80%9EPablo%20Stanley%E2%80%9D%2C%20licensed%20under%20%E2%80%9EFree%20for%20personal%20and%20commercial%20use%E2%80%9D%20(https%3A%2F%2Fbottts.com%2F)%3C%2Fdc%3Arights%3E%3C%2Frdf%3ADescription%3E%3C%2Frdf%3ARDF%3E%3C%2Fmetadata%3E%3Cmask%20id%3D%22viewboxMask%22%3E%3Crect%20width%3D%22180%22%20height%3D%22180%22%20rx%3D%220%22%20ry%3D%220%22%20x%3D%220%22%20y%3D%220%22%20fill%3D%22%23fff%22%20%2F%3E%3C%2Fmask%3E%3Cg%20mask%3D%22url(%23viewboxMask)%22%3E%3Crect%20fill%3D%22%23ffdfbf%22%20width%3D%22180%22%20height%3D%22180%22%20x%3D%220%22%20y%3D%220%22%20%2F%3E%3Cg%20transform%3D%22translate(0%2066)%22%3E%3Cmask%20id%3D%22sidesSquareAssymetric-a%22%20style%3D%22mask-type%3Aluminance%22%20maskUnits%3D%22userSpaceOnUse%22%20x%3D%2210%22%20y%3D%228%22%20width%3D%22165%22%20height%3D%2260%22%3E%3Cg%20fill%3D%22%23fff%22%3E%3Crect%20x%3D%2210%22%20y%3D%2231%22%20width%3D%2236%22%20height%3D%2230%22%20rx%3D%224%22%2F%3E%3Crect%20x%3D%2220%22%20y%3D%2215%22%20width%3D%2226%22%20height%3D%2230%22%20rx%3D%224%22%2F%3E%3Crect%20x%3D%22139%22%20y%3D%2223%22%20width%3D%2236%22%20height%3D%2230%22%20rx%3D%224%22%2F%3E%3Crect%20x%3D%22134%22%20y%3D%228%22%20width%3D%2236%22%20height%3D%2260%22%20rx%3D%224%22%2F%3E%3C%2Fg%3E%3C%2Fmask%3E%3Cg%20mask%3D%22url(%23sidesSquareAssymetric-a)%22%3E%3Cpath%20d%3D%22M0%200h180v76H0V0Z%22%20fill%3D%22%235e35b1%22%2F%3E%3Cpath%20d%3D%22M0%200h180v76H0V0Z%22%20fill%3D%22%23fff%22%20fill-opacity%3D%22.3%22%2F%3E%3Cpath%20fill%3D%22%23000%22%20fill-opacity%3D%22.1%22%20d%3D%22M0%2047h180v29H0z%22%2F%3E%3Ccircle%20cx%3D%22161%22%20cy%3D%2220%22%20r%3D%225%22%20fill%3D%22%23fff%22%20fill-opacity%3D%22.6%22%2F%3E%3Ccircle%20cx%3D%22161%22%20cy%3D%2236%22%20r%3D%225%22%20fill%3D%22%23fff%22%20fill-opacity%3D%22.6%22%2F%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(41)%22%3E%3Cmask%20id%3D%22topAntenna-a%22%20style%3D%22mask-type%3Aluminance%22%20maskUnits%3D%22userSpaceOnUse%22%20x%3D%2238%22%20y%3D%225%22%20width%3D%2224%22%20height%3D%2247%22%3E%3Cpath%20d%3D%22M38%2038c0-1.1.9-2%202-2h20a2%202%200%200%201%202%202v14H38V38ZM48%205h4v31h-4z%22%20fill%3D%22%23fff%22%2F%3E%3C%2Fmask%3E%3Cg%20mask%3D%22url(%23topAntenna-a)%22%3E%3Cpath%20d%3D%22M0%200h100v52H0V0Z%22%20fill%3D%22%235e35b1%22%2F%3E%3Cpath%20d%3D%22M0%203h100v52H0V3Z%22%20fill%3D%22%23fff%22%20fill-opacity%3D%22.3%22%2F%3E%3Cpath%20fill%3D%22%23fff%22%20fill-opacity%3D%22.2%22%20d%3D%22M38%2036h24v16H38z%22%2F%3E%3C%2Fg%3E%3Ccircle%20cx%3D%2250%22%20cy%3D%228%22%20r%3D%228%22%20fill%3D%22%23FFE65C%22%2F%3E%3Ccircle%20cx%3D%2253%22%20cy%3D%225%22%20r%3D%223%22%20fill%3D%22%23fff%22%2F%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(25%2044)%22%3E%3Cmask%20id%3D%22faceSquare02-a%22%20style%3D%22mask-type%3Aluminance%22%20maskUnits%3D%22userSpaceOnUse%22%20x%3D%220%22%20y%3D%220%22%20width%3D%22130%22%20height%3D%22120%22%3E%3Cpath%20d%3D%22M0%2012A12%2012%200%200%201%2012%200h106a12%2012%200%200%201%2012%2012v70a38%2038%200%200%201-38%2038H38A38%2038%200%200%201%200%2082V12Z%22%20fill%3D%22%23fff%22%2F%3E%3C%2Fmask%3E%3Cg%20mask%3D%22url(%23faceSquare02-a)%22%3E%3Cpath%20d%3D%22M-2-2h134v124H-2V-2Z%22%20fill%3D%22%235e35b1%22%2F%3E%3Cg%20transform%3D%22translate(-1%20-1)%22%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(52%20124)%22%3E%3Crect%20x%3D%224%22%20y%3D%224%22%20width%3D%2268%22%20height%3D%2224%22%20rx%3D%225%22%20fill%3D%22%23000%22%20fill-opacity%3D%22.2%22%2F%3E%3Crect%20x%3D%228%22%20y%3D%228%22%20width%3D%2260%22%20height%3D%2216%22%20rx%3D%222%22%20fill%3D%22%23000%22%20fill-opacity%3D%22.8%22%2F%3E%3Cpath%20d%3D%22M9%2017h11l2-4%203%207%204-8%202%209%203-11%203%2010%203-3h15l3-4%202%207%203-3h4%22%20stroke%3D%22%234EFAC9%22%20stroke-width%3D%222%22%20stroke-linecap%3D%22round%22%20stroke-linejoin%3D%22round%22%2F%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(38%2076)%22%3E%3Cg%20fill-rule%3D%22evenodd%22%20clip-rule%3D%22evenodd%22%3E%3Cpath%20d%3D%22M53%200c34.75%200%2049%2017.47%2049%2031%200%2013.53-19.59%2017-49%2017-29.05%200-51-3.47-51-17S17.11%200%2053%200Z%22%20fill%3D%22%23000%22%20fill-opacity%3D%22.8%22%2F%3E%3Cpath%20d%3D%22M28.82%2034.65c-6.53-1.35-11.24-6.34-10.52-11.14.72-4.79%206.6-7.58%2013.12-6.23%206.53%201.36%2011.24%206.35%2010.52%2011.15-.72%204.8-6.6%207.59-13.12%206.23ZM75.42%2034.65c-6.52%201.36-12.4-1.43-13.12-6.23-.72-4.8%204-9.8%2010.52-11.15%206.52-1.35%2012.4%201.44%2013.12%206.24.72%204.81-4%209.8-10.52%2011.15Z%22%20fill%3D%22%2325A6F5%22%2F%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fsvg%3E)
%20by%20%E2%80%9EPablo%20Stanley%E2%80%9D%2C%20licensed%20under%20%E2%80%9EFree%20for%20personal%20and%20commercial%20use%E2%80%9D%20(https%3A%2F%2Favataaars.com%2F)%3C%2Fdc%3Arights%3E%3C%2Frdf%3ADescription%3E%3C%2Frdf%3ARDF%3E%3C%2Fmetadata%3E%3Cmask%20id%3D%22viewboxMask%22%3E%3Crect%20width%3D%22280%22%20height%3D%22280%22%20rx%3D%220%22%20ry%3D%220%22%20x%3D%220%22%20y%3D%220%22%20fill%3D%22%23fff%22%20%2F%3E%3C%2Fmask%3E%3Cg%20mask%3D%22url(%23viewboxMask)%22%3E%3Crect%20fill%3D%22%23b6e3f4%22%20width%3D%22280%22%20height%3D%22280%22%20x%3D%220%22%20y%3D%220%22%20%2F%3E%3Cg%20transform%3D%22translate(8)%22%3E%3Cpath%20d%3D%22M132%2036a56%2056%200%200%200-56%2056v6.17A12%2012%200%200%200%2066%20110v14a12%2012%200%200%200%2010.3%2011.88%2056.04%2056.04%200%200%200%2031.7%2044.73v18.4h-4a72%2072%200%200%200-72%2072v9h200v-9a72%2072%200%200%200-72-72h-4v-18.39a56.04%2056.04%200%200%200%2031.7-44.73A12%2012%200%200%200%20198%20124v-14a12%2012%200%200%200-10-11.83V92a56%2056%200%200%200-56-56Z%22%20fill%3D%22%23ffdbb4%22%2F%3E%3Cpath%20d%3D%22M108%20180.61v8a55.79%2055.79%200%200%200%2024%205.39c8.59%200%2016.73-1.93%2024-5.39v-8a55.79%2055.79%200%200%201-24%205.39%2055.79%2055.79%200%200%201-24-5.39Z%22%20fill%3D%22%23000%22%20fill-opacity%3D%22.1%22%2F%3E%3Cg%20transform%3D%22translate(0%20170)%22%3E%3Cpath%20d%3D%22M196%2038.63V110H68V38.63a71.52%2071.52%200%200%201%2026-8.94v44.3h76V29.69a71.52%2071.52%200%200%201%2026%208.94Z%22%20fill%3D%22%23b1e2ff%22%2F%3E%3Cpath%20d%3D%22M86%2083a5%205%200%201%201-10%200%205%205%200%200%201%2010%200ZM188%2083a5%205%200%201%201-10%200%205%205%200%200%201%2010%200Z%22%20fill%3D%22%23F4F4F4%22%2F%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(78%20134)%22%3E%3Cpath%20fill-rule%3D%22evenodd%22%20clip-rule%3D%22evenodd%22%20d%3D%22M40%2015a14%2014%200%201%200%2028%200%22%20fill%3D%22%23000%22%20fill-opacity%3D%22.7%22%2F%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(104%20122)%22%3E%3Cpath%20fill-rule%3D%22evenodd%22%20clip-rule%3D%22evenodd%22%20d%3D%22M16%208c0%204.42%205.37%208%2012%208s12-3.58%2012-8%22%20fill%3D%22%23000%22%20fill-opacity%3D%22.16%22%2F%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(76%2090)%22%3E%3Cpath%20d%3D%22M34.5%2030.7%2029%2025.2l-5.5%205.5c-.4.4-1.1.4-1.6%200l-1.6-1.6c-.4-.4-.4-1.1%200-1.6l5.5-5.5-5.5-5.5c-.4-.5-.4-1.2%200-1.6l1.6-1.6c.4-.4%201.1-.4%201.6%200l5.5%205.5%205.5-5.5c.4-.4%201.1-.4%201.6%200l1.6%201.6c.4.4.4%201.1%200%201.6L32.2%2022l5.5%205.5c.4.4.4%201.1%200%201.6l-1.6%201.6c-.4.4-1.1.4-1.6%200ZM88.5%2030.7%2083%2025.2l-5.5%205.5c-.4.4-1.1.4-1.6%200l-1.6-1.6c-.4-.4-.4-1.1%200-1.6l5.5-5.5-5.5-5.5c-.4-.5-.4-1.2%200-1.6l1.6-1.6c.4-.4%201.1-.4%201.6%200l5.5%205.5%205.5-5.5c.4-.4%201.1-.4%201.6%200l1.6%201.6c.4.4.4%201.1%200%201.6L86.2%2022l5.5%205.5c.4.4.4%201.1%200%201.6l-1.6%201.6c-.4.4-1.1.4-1.6%200Z%22%20fill%3D%22%23000%22%20fill-opacity%3D%22.6%22%2F%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(76%2082)%22%3E%3Cpath%20d%3D%22M44.1%2017.12ZM19.27%205.01a7.16%207.16%200%200%200-6.42%202.43c-.6.73-1.56%202.48-1.51%203.42.02.35.22.37%201.12.59%201.65.39%204.5-1.12%206.36-.98%202.58.2%205.04%201.4%207.28%202.68%203.84%202.2%208.35%206.84%2013.1%206.6.35-.02%205.41-1.74%204.4-2.72-.31-.49-3.03-1.13-3.5-1.36-2.17-1.09-4.37-2.45-6.44-3.72C29.14%209.18%2024.72%205.6%2019.28%205ZM68.03%2017.12ZM92.91%205.01c2.36-.27%204.85.5%206.42%202.43.6.73%201.56%202.48%201.51%203.42-.02.35-.22.37-1.12.59-1.65.39-4.5-1.12-6.36-.98-2.58.2-5.04%201.4-7.28%202.68-3.84%202.2-8.35%206.84-13.1%206.6-.35-.02-5.41-1.74-4.4-2.72.31-.49%203.03-1.13%203.5-1.36%202.17-1.09%204.36-2.45%206.44-3.72C83.05%209.18%2087.46%205.6%2092.91%205Z%22%20fill-rule%3D%22evenodd%22%20clip-rule%3D%22evenodd%22%20fill%3D%22%23000%22%20fill-opacity%3D%22.6%22%2F%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(-1)%22%3E%3Cpath%20d%3D%22M44.83%20105.6c-.39-1.61-.77-3.24-1.13-4.92-1.95-9.23-2.95-20.22%202.89-39.67-6.9%2022.99-4.25%2034.15-1.76%2044.58%201.23%205.2%202.43%2010.2%202.37%2016.4a15.44%2015.44%200%200%200%200%200c.06-6.2-1.14-11.21-2.37-16.4ZM218.38%20114.23c-.13.4-.16.8-.18%201.23l.18-1.23ZM218.05%20116.81c-.11%201.09-.2%202.2-.23%203.35-29.04-10.76-54.94-29.62-70.32-51.55-12.1%2015.62-31.96%2023.04-51.63%2030.4-17.38%206.5-34.62%2012.94-46.2%2024.94l1.09-1.5c11-14.6%2028.76-21.88%2046.7-29.24%2018.82-7.71%2037.82-15.5%2049.39-31.9%2015.4%2024.1%2041.81%2044.65%2071.16%2055.63l.04-.12Z%22%20fill%3D%22%23000%22%20fill-opacity%3D%22.16%22%2F%3E%3Cpath%20d%3D%22M32%20280h1v-9a72%2072%200%200%201%2072-72h4v-18.39a56.03%2056.03%200%200%201-31.8-45.74A12%2012%200%200%201%2067%20123v-13c0-.8.08-1.57.22-2.32%209.12-5.82%2019.65-10.13%2030.24-14.48%2018.81-7.71%2037.82-15.5%2049.39-31.9C158.8%2080%20177.4%2096.6%20198.87%20108.2c.08.59.13%201.19.13%201.8v13a12%2012%200%200%201-10.2%2011.87A56.03%2056.03%200%200%201%20157%20180.6V199h4a72%2072%200%200%201%2072%2072v9c24.41-13.94%2015.86-33.21%206.28-48.46a303.17%20303.17%200%200%200-4.07-6.27c-3.48-5.25-6.45-9.74-7.2-12.97-.1-.46-.17-.9-.18-1.3-.14-4.62%203.14-7.84%207.16-11.78%206.22-6.08%2014.18-13.89%2014.01-31.22-.51-15.83-9.8-22.25-18.1-28-6.93-4.78-13.17-9.1-13.1-18-.01-1.82.08-3.54.25-5.19.11-.4.13-.83.15-1.25v-.1c.45-3.44%201.2-6.62%201.98-9.87%202.55-10.72%205.3-22.23-2.38-46.59-2.9-9.12-6.97-16.5-12.1-22.46-14.12-16.42-36.35-22.04-64.9-23.29-2.55-.11-5.15-.19-7.8-.23V13h-1c-43.08.77-73.16%209.54-84.8%2046-7.67%2024.36-4.93%2035.87-2.37%2046.6%201.23%205.19%202.43%2010.2%202.37%2016.4.03%203.75-1.06%206.7-2.85%209.2-2.46%203.43-6.23%206.04-10.24%208.8-8.3%205.75-17.6%2012.17-18.1%2028-.17%2017.33%207.8%2025.14%2014.01%2031.22%204.03%203.94%207.32%207.16%207.17%2011.78-.08%203.26-3.4%208.27-7.38%2014.27-10.54%2015.9-25.7%2038.8%202.2%2054.73Z%22%20fill%3D%22%23c93305%22%2F%3E%3Cpath%20fill-rule%3D%22evenodd%22%20clip-rule%3D%22evenodd%22%20d%3D%22M50.58%20122.45c22.54-29.92%2073.49-29.13%2096.09-61.15%2015.4%2024.1%2041.82%2044.65%2071.16%2055.63.3-.86.08-1.85.37-2.7%202.15-14.14%209.14-24.37-.58-55.23-11.63-36.46-41.71-45.23-84.8-45.98l-1-.02c-43.08.77-73.16%209.54-84.8%2046-11.38%2036.16.17%2044%200%2063%20.04%203.75-1.05%206.7-2.85%209.2.19.4%204.16-5.76%206.41-8.75Z%22%20fill%3D%22%23fff%22%20fill-opacity%3D%22.2%22%2F%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(49%2072)%22%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(62%2042)%22%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fsvg%3E)
%20by%20%E2%80%9ELisa%20Wischofsky%E2%80%9D%2C%20licensed%20under%20%E2%80%9ECC0%201.0%E2%80%9D%20(https%3A%2F%2Fcreativecommons.org%2Fpublicdomain%2Fzero%2F1.0%2F)%3C%2Fdc%3Arights%3E%3C%2Frdf%3ADescription%3E%3C%2Frdf%3ARDF%3E%3C%2Fmetadata%3E%3Cmask%20id%3D%22viewboxMask%22%3E%3Crect%20width%3D%22980%22%20height%3D%22980%22%20rx%3D%220%22%20ry%3D%220%22%20x%3D%220%22%20y%3D%220%22%20fill%3D%22%23fff%22%20%2F%3E%3C%2Fmask%3E%3Cg%20mask%3D%22url(%23viewboxMask)%22%3E%3Crect%20fill%3D%22%23b6e3f4%22%20width%3D%22980%22%20height%3D%22980%22%20x%3D%220%22%20y%3D%220%22%20%2F%3E%3Cg%20transform%3D%22translate(10%20-60)%22%3E%3Cpath%20d%3D%22M586%20147c15-1%2029%201%2042%208%204%202%208%202%2011%205%202%203%201%207-2%209-3%201-6-1-9-2h-28a95%2095%200%200%200-79%2057c15-7%2030-13%2047-14%2014-2%2028-1%2042%202%2029%207%2056%2021%2078%2041%2020%2018%2035%2041%2043%2066l3%2011c10%2020%2017%2043%2018%2066%202%2036-9%2073-33%20101-11%2013-23%2023-38%2032l4%2044%201%2017a143%20143%200%200%201-111%20128c-17%204-35%206-52%205h-33c-23%201-47%207-69%2015l-24%207c-11%203-23%201-34%203a79%2079%200%200%201-57-22c-8%202-15%205-23%204s-16-4-20-11c3-1%206-2%209-5%205-5%206-12%205-19-1-16-7-29-14-43l-17-36-14-30-23-52a211%20211%200%200%201-3-160%20282%20282%200%200%201%20148-154c26-10%2055-17%2083-14%2016%201%2034%206%2047%2016-1-9%204-18%209-26%2012-18%2033-32%2053-40%2013-6%2026-8%2040-9Z%22%20fill%3D%22%23000000%22%2F%3E%3Cpath%20d%3D%22M486%20236c57-2%20115%2018%20159%2056a209%20209%200%200%201%2073%20190c-1%204-1%208-4%2012l-1-3v-33a215%20215%200%200%200-172-206%20235%20235%200%200%200-270%20153c-12%2037-14%2078-6%20116%206-2%2012-2%2017-2%202%201%205%201%206%203s0%203-1%204l-12%204c-14%203-27%208-37%2018a63%2063%200%200%200-22%2045c0%2012%203%2024%208%2035%208%2013%2019%2024%2033%2031%2018%2010%2041%2013%2062%207%202-1%204-2%206-1s3%204%204%206l15%2030a215%20215%200%200%200%2072%2063c28%2015%2059%2021%2090%2026%203%201%208%201%2010%204%201%202%200%203-2%204l-11%201a231%20231%200%200%201-147-62c5%2018%208%2036%208%2054%200%2012-2%2023-6%2034-5%2010-11%2018-19%2026a196%20196%200%200%201-60%2043c-1-1%201-2%202-3l17-14c13-12%2025-23%2035-38a93%2093%200%200%200%2017-65l-4-39-2-10-12-17c-5-10-11-20-13-31a93%2093%200%200%201-96-31%2081%2081%200%200%201-19-51c0-12%203-23%208-34%209-16%2023-29%2040-36-8-31-8-62-3-93%208-40%2026-77%2051-108%2045-54%20115-87%20186-88Z%22%20fill%3D%22%23000%22%2F%3E%3Cpath%20d%3D%22M541%20252a214%20214%200%200%201%20172%20206v33c-1%205-2%2010-1%2015-2%202-3%203-3%205-3%2018-1%2037%201%2055%204%2029%206%2059%202%2088-3%2028-13%2056-30%2079-16%2021-38%2034-62%2043-15%206-30%209-45%2013-11%202-22%204-32%208%201%202%204%201%206%202%2012%201%2024-1%2036-2-5%208-8%2017-9%2026-2%2010%202%2019%209%2026%206%207%2015%2011%2024%2014%205%202%2011%203%2017%203%207%209%2013%2018%2014%2030%202%2012-1%2024-8%2034-9%2014-22%2023-37%2030-18%209-38%2015-57%2018a352%20352%200%200%201-192-23c-18-10-38-23-48-42-4-7-8-16-6-24%2018-10%2033-23%2047-38%208-8%2014-16%2019-26%204-11%206-22%206-34%200-18-3-36-8-54a235%20235%200%200%200%20147%2062l11-1c2-1%203-2%202-4-2-3-7-3-10-4-31-5-62-11-90-26-18-10-36-22-50-37-8-8-16-17-22-26l-15-30c-1-2-2-5-4-6s-4%200-6%201a82%2082%200%200%201-95-38c-5-11-8-23-8-35%201-17%209-34%2022-45%2010-10%2023-15%2037-18l12-4c1-1%202-2%201-4s-4-2-6-3c-5%200-11%200-17%202-8-38-6-79%206-116a236%20236%200%200%201%20270-153Z%22%20fill%3D%22%23ffffff%22%2F%3E%3Cpath%20d%3D%22m712%20506%203%203%201%2013%203%2045c3%2020%205%2040%205%2060%200%2016-1%2032-5%2047-6%2028-20%2056-40%2076a174%20174%200%200%201-88%2046c-1%209-4%2016-4%2025-1%206%202%2010%205%2015%208%208%2018%2014%2028%2019l18%209c-3%203-8%201-12%202-6%200-12-1-17-3-9-3-18-7-24-14-7-7-11-16-9-26%201-9%204-18%209-26-12%201-24%203-36%202-2-1-5%200-6-2%2010-4%2021-6%2032-8%2015-4%2030-7%2045-13%2024-9%2046-22%2062-43%2017-23%2027-51%2030-79%204-29%202-59-2-88-2-18-4-37-1-55%200-2%201-3%203-5ZM262%20566c6%200%2012%201%2015%206%202%203%202%207%201%2010-3%208-9%2014-11%2022-1%204%200%207%203%209%207%205%2016%207%2024%2010l-2%202h-11c-6-1-12-2-17-5-5-4-9-11-7-18%202-9%209-15%2012-23-7-4-14-2-20-8%203-4%208-6%2013-5Z%22%20fill%3D%22%23000%22%2F%3E%3Cpath%20d%3D%22M665%20473c7-1%2015-1%2022%203%206%204%2010%209%2011%2016l17%203c-4%204-11%206-17%206-5%200-11-1-15-4l-10-8c-6-3-11-2-17%200%203%203%206%206%207%2010%204%2012%203%2025-2%2036l10-5c1%206-1%2010-5%2013-8%209-21%2010-33%2010-4-1-10-3-12-7-3-4-1-8-3-12s-1-9%200-13a70%2070%200%200%201%2047-48ZM457%20484c27%201%2052%2018%2064%2042%202%202%203%206%201%209-3%200-5-4-7-6-6-10-14-18-23-24-10-6-21-8-32-8%206%2010%209%2022%208%2033-1%209-5%2019-12%2025l9%204c-6%203-12%203-18%202-11-3-21-8-30-15-9-6-16-15-19-25-14%200-29-2-43-8%203-2%205-2%208-2l28-4c4-1%208-1%2011-4%2015-13%2035-20%2055-19Z%22%20fill%3D%22%23000000%22%2F%3E%3Cpath%20d%3D%22M492%20386c7%200%2013%200%2019%202%208%202%2015%205%2018%2013%204%207%204%2014%202%2022-1%204-4%207-9%208-8%203-17%201-26-1-7-1-15-3-22-6-6-3-12-8-13-14-2-6%202-13%207-16%207-6%2016-7%2024-8ZM658%20388c5%201%209%204%2011%209%202%203%201%208%200%2011-1%204-5%208-8%2010-5%205-11%206-18%208-5%201-12%203-18%201-2-1-6-4-7-7-3-11%203-25%2014-30%208-4%2017-4%2026-2Z%22%20fill%3D%22%23000000%22%2F%3E%3Cpath%20d%3D%22M216%20569c5%200%2010-1%2014%202%203%202%205%205%204%209-2%204-6%207-11%207h-16c-5-1-9-3-11-7-1-4%202-7%205-9%205-2%2010-1%2015-2ZM229%20592c3%201%207%203%207%207%200%203-1%206-4%207-5%204-11%204-17%206-5%201-10%202-14-1s-3-9%200-12c4-4%208-4%2013-5s10-3%2015-2ZM301%20644h8c3%201%206%204%206%208%200%205-4%209-9%2010-5%202-9-2-11-6-1-5%201-11%206-12Z%22%20fill%3D%22%23000000%22%2F%3E%3Cpath%20d%3D%22M597%20505h1l3%2015%203%2026%208%2013%206%2012c2%205%202%2010%205%2014%203%205%205%2010%205%2016%200%209-6%2017-14%2020l-19%208c-5%203-9%205-15%205-5%200-11%200-13-5-2-2%200-4%202-5l12-3%2016-5%2013-5c6-2%209-8%207-14l-5-8-7-17-7-19c-4-8-6-17-5-26%200-7%201-15%204-22Z%22%20fill%3D%22%23000000%22%2F%3E%3Cpath%20d%3D%22M599%20665c5%200%2010%203%2013%207%203%206%204%2013%205%2020%201%2011-1%2023-6%2033-5%209-13%2013-22%2015-11%203-23%203-34%203-4%200-9-1-13-3%207-3%2013-3%2020-4l21-3c6-1%2014-4%2018-9s6-12%207-19l-4%206c-4%203-9%203-14%204l-26%204c-7%201-15%203-23%200l-11%2023c-3%201-3-2-3-4%200-7%203-14%206-20%207-17%2021-32%2036-42%209-6%2019-11%2030-11Z%22%20fill%3D%22%23000000%22%2F%3E%3Cpath%20d%3D%22m618%20150%2017%207c2%202%205%204%205%207-1%203-4%206-7%205-10-3-21-3-32-2a95%2095%200%200%200-80%2057%20127%20127%200%200%201%20100-9c19%206%2037%2015%2054%2026a153%20153%200%200%201%2062%20138c-2%2016-6%2031-14%2045-6%2010-13%2018-22%2025s-18%2011-27%2016c-5%202-11%204-16%203l-4-1v-10c-1-13-4-27-7-40-6-22-14-43-24-64-8-14-16-30-28-41%2010%2021%2015%2045%2013%2069-1%2019-6%2037-12%2055-7%2017-16%2034-29%2048-6%206-14%2012-22%2013l6-12%207-27c2-13%204-26%204-39a158%20158%200%200%201-59%2078c-5%203-12%206-19%207-3%200-5-3-4-6l7-9c11-16%2020-33%2027-51%209-22%2012-45%2012-68a362%20362%200%200%201-48%2078c-15%2015-31%2027-50%2037l-26%2013c-4%201-8%203-11%200a783%20783%200%200%200%2013-72c1-18-1-36-4-54-1%208-4%2016-8%2023-9%2018-23%2034-38%2048l-1%205c-2%2014-3%2029-2%2043%201%2015%204%2028%208%2042%202%208%206%2015%209%2023%201%202%202%204%201%207s-4%204-7%204a96%2096%200%200%201-61-13c-3-2-5-5-10-5-28-1-56-13-75-34-13-16-20-36-23-56-3-29%202-57%2012-84a281%20281%200%200%201%20149-155c26-10%2055-17%2083-14%2016%201%2034%206%2047%2016-1-9%203-17%208-24a128%20128%200%200%201%2078-49c15-3%2033-4%2048%201Z%22%20fill%3D%22%23000000%22%2F%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(10%20-60)%22%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fsvg%3E)
%20by%20%E2%80%9EDiceBear%E2%80%9D%2C%20licensed%20under%20%E2%80%9ECC0%201.0%E2%80%9D%20(https%3A%2F%2Fcreativecommons.org%2Fpublicdomain%2Fzero%2F1.0%2F)%3C%2Fdc%3Arights%3E%3C%2Frdf%3ADescription%3E%3C%2Frdf%3ARDF%3E%3C%2Fmetadata%3E%3Cmask%20id%3D%22viewboxMask%22%3E%3Crect%20width%3D%225%22%20height%3D%225%22%20rx%3D%220%22%20ry%3D%220%22%20x%3D%220%22%20y%3D%220%22%20fill%3D%22%23fff%22%20%2F%3E%3C%2Fmask%3E%3Cg%20mask%3D%22url(%23viewboxMask)%22%3E%3Crect%20fill%3D%22%23b6e3f4%22%20width%3D%225%22%20height%3D%225%22%20x%3D%220%22%20y%3D%220%22%20%2F%3E%3Cpath%20d%3D%22M1%200H0v1h1V0ZM5%200H4v1h1V0Z%22%20fill%3D%22%235e35b1%22%2F%3E%3Cpath%20fill%3D%22%235e35b1%22%20d%3D%22M1%201h3v1H1z%22%2F%3E%3Cpath%20d%3D%22M0%202h1v1H0V2ZM4%202h1v1H4V2ZM3%202H2v1h1V2Z%22%20fill%3D%22%235e35b1%22%2F%3E%3Cpath%20d%3D%22M2%203H1v1h1V3ZM4%203H3v1h1V3Z%22%20fill%3D%22%235e35b1%22%2F%3E%3Cpath%20fill%3D%22%235e35b1%22%20d%3D%22M1%204h3v1H1z%22%2F%3E%3C%2Fg%3E%3C%2Fsvg%3E)