1.为何需要大数据解决方案:
随着各个业务系统的不断增加,以及各业务系统数据量不断激增,IT数据支撑方的工作变得越来越复杂。主要问题如下:
- 数据来自多个不同的系统,存在需要跨数据源分析,需要对接各种不同数据源等问题。
- 需要分析的数据体量越来越大,并且要快速获得分析结果的问题。
供数支撑方在业务系统的前端看起来基本没有任何操作,但背后的逻辑十分复杂,实现难度也很大。就像看得到的是冰山一角,看不到的是海水下绝大部分的支撑。
这个时候急需要大数据解决方案。
举个例子:FineBI为了适应大数据时代,完善大数据解决方案,解决日益激增的大数据量分析诉求,为数据分析展示的最后一公里做好支撑。自助式商业智能分析bi工具FineBI V6.0版本的Spider引擎应运而生。
2.怎么支撑大数据解决方案:
finebi有基于Spider大数据引擎的直连模式和本地模式,可支撑BI数据分析的各种应用场景。
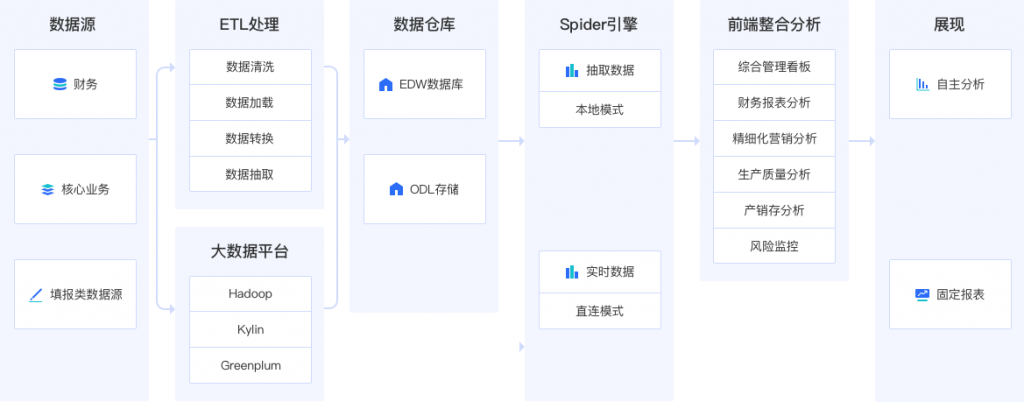
同时拥有以下的技术:
抽取数据的存储是以列为单位的, 同一列数据连续存储,在查询时可以大幅降低I/O,提高查询效率,并且连续存储的列数据,具有更大的压缩单元和数据相似性,可以大幅提高压缩效率。
位图索引即Bitmap索引,是处理大数据时加快过滤速度的一种常见技术,并且可以利用位图索引实现大数据量并发计算,并指数级的提升查询效率,同时我们做了压缩处理,使得数据占用空间大大降低。
为了减少网络传输的消耗,避免不必要的shuffle,利用Spark的调度机制实现数据本地化计算。在知道数据位置的前提下,将任务分配到拥有计算数据的节点上,节省了数据传输的消耗,完成巨量数据计算的秒级呈现。
直连模式下会直接和数据库对话,性能会受到数据库的限制,因此引入encache框架做智能缓存,以及针对返回数据之后的操作有多级缓存和智能命中策略,避免重复缓存,从而大幅提升查询性能。
3.大数据解决方案落地实例:
保险行业的明细分析应用
在保险行业,有大数据量明细清单查询与分析场景,这种场景在稍大型保险企业,明细数据量动辄上亿。
保险行业常用传统展示分析工具如BO、SSAS、cognos、Microstrategy等,常规汇总分析数据与粗粒度维度汇总计算较为方便,固定的指标查看等都没有问题。但是到明细数据的展示分析与汇总时候,就存在各种性能瓶颈以及传统BI工具的约束,比如维度过多导致cube难以支撑; 无法在线查看实际明细数据,而下载导出的数据有数据量的限制;任意维度调整、查询条件改变都需要IT人员的修改;图表可视化效果一般等。
因此使用FineBI及其Spider引擎来做补足。从而实现:
更多明细数据全维度展示分析:承保、批改、理赔、再报、收付、客服六大环节明细数据实现全维度分析。数据校验、核对:检验统计指标的计算正确性,支付金额的确认与核对,以及结算对账等。问题深入挖掘:从粗粒度统计报表维度结论追朔到明细清单层面,发现问题并处理。任务完成情况跟踪:未决清单情况的跟踪等。
商业智能BI产品更多介绍:www.finebi.com
免费下载FineBI
立即体验Demo
 电话咨询:400-811-8890
电话咨询:400-811-8890