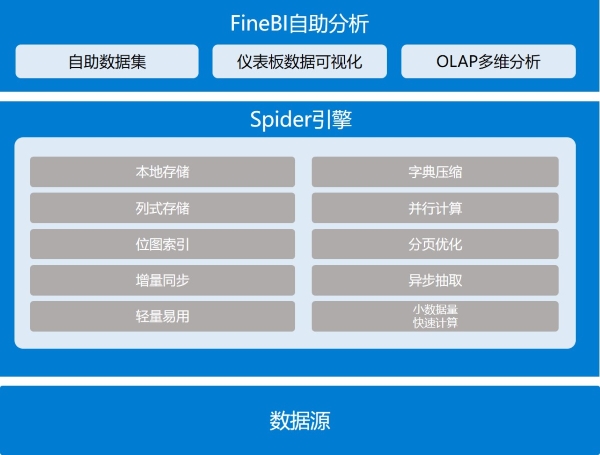
FineBI Spider高性能计算引擎,以轻量级的架构实现大数据分析
- 存储高压缩:先进列式存储,大幅降低磁盘IO,强大的数据压缩,让数据占用存储空间大幅降低,节省磁盘空间。
- 本地与直连双模式切换:支持本地与直连双模式切换,可以依托数据库的计算性能实现前端的快速展现和分析。
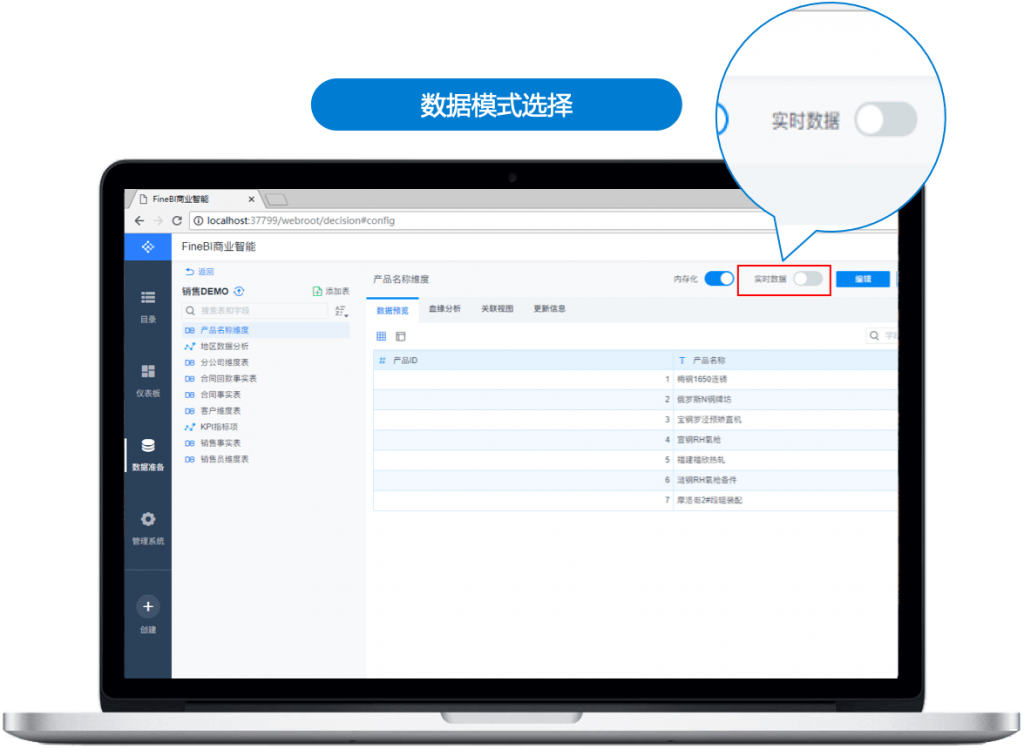
FineBI Spider引擎支持实时数据与抽取数据两种模式,更可无缝切换
- 抽取数据:提供基于索引的高效计算引擎,通过数据预加载,支撑前端快速数据分析,适用于实时性要求不高的大数据分析场景。
- 实时数据:直接对接读取企业的数据库表进行分析,适用于对实时性要求较高的大数据分析场景。
FineBI Spider引擎的高性能可轻松实现亿级以内的数据秒级呈现
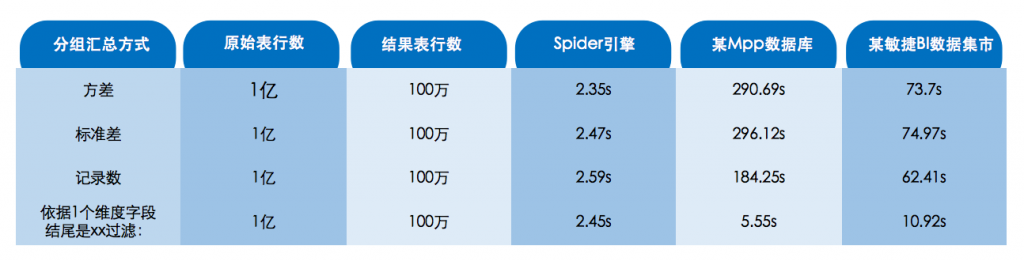
大数据测试场景举例(1亿条数据量):分组汇总(含第三方对比)
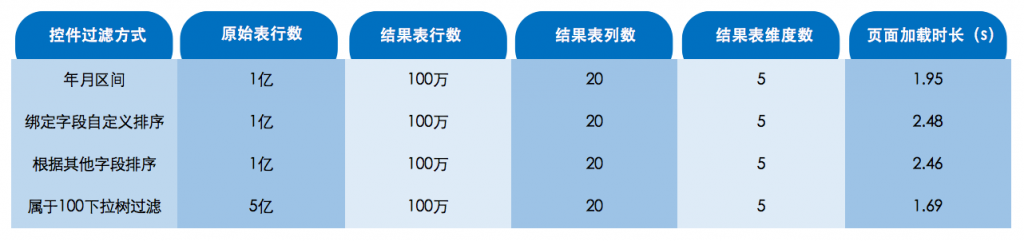
大数据测试场景举例(1亿条数据量):控件过滤
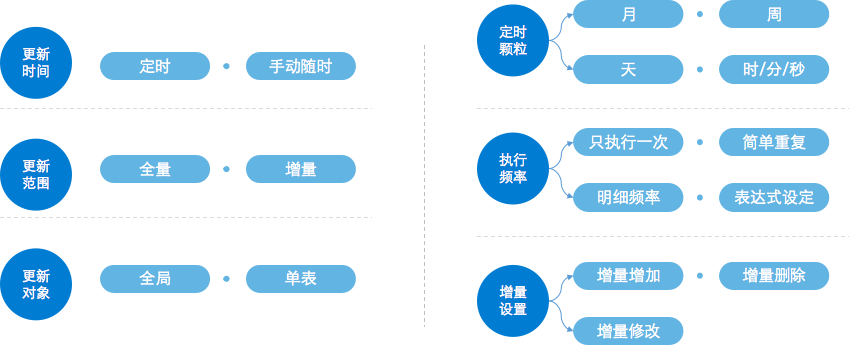
FineBI Spider引擎支持灵活的数据更新策略,让数据准备更加高效