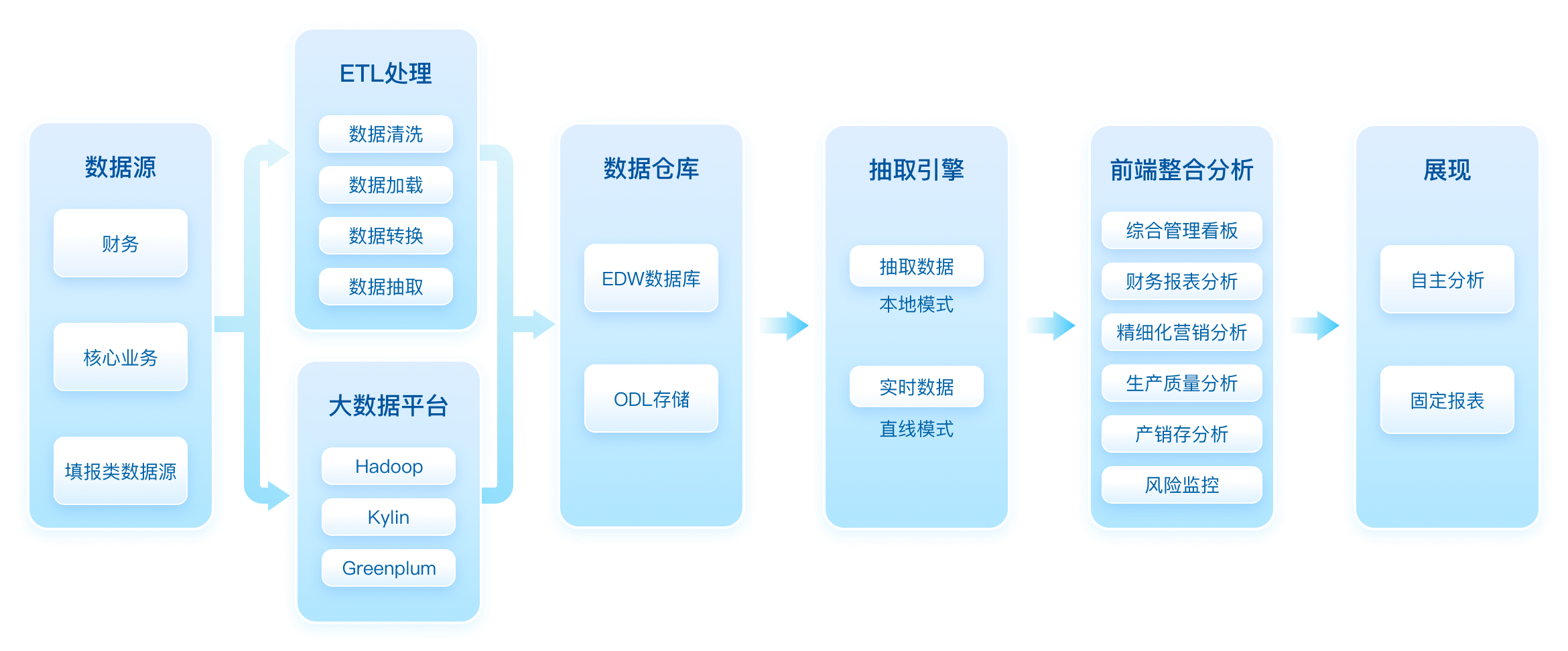
随着企业数字化的发展,业务系统数量不断增加,各业务系统数据量也不断激增,IT数据支撑方的工作变得越来越复杂。主要问题如下:

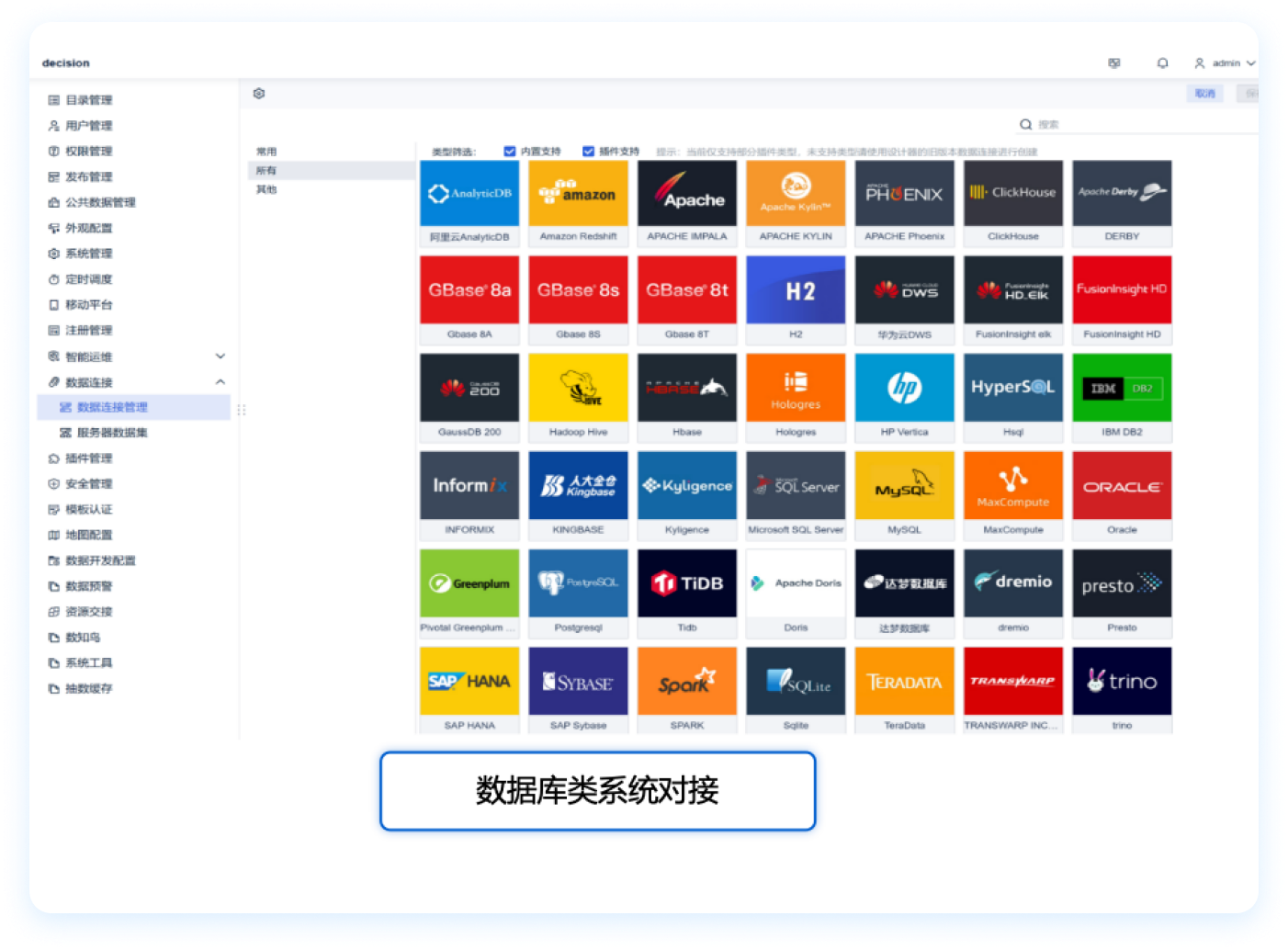
数据来自多个不同的业务系统,需要对接各种数据源并整合成统一数据仓库

积累的数据越来越多,数据体量越来越大,但对数据分析的要求越来越高

获取到源数据后,往往都要再对数据进行清洗、合并、过滤等二次加工操作
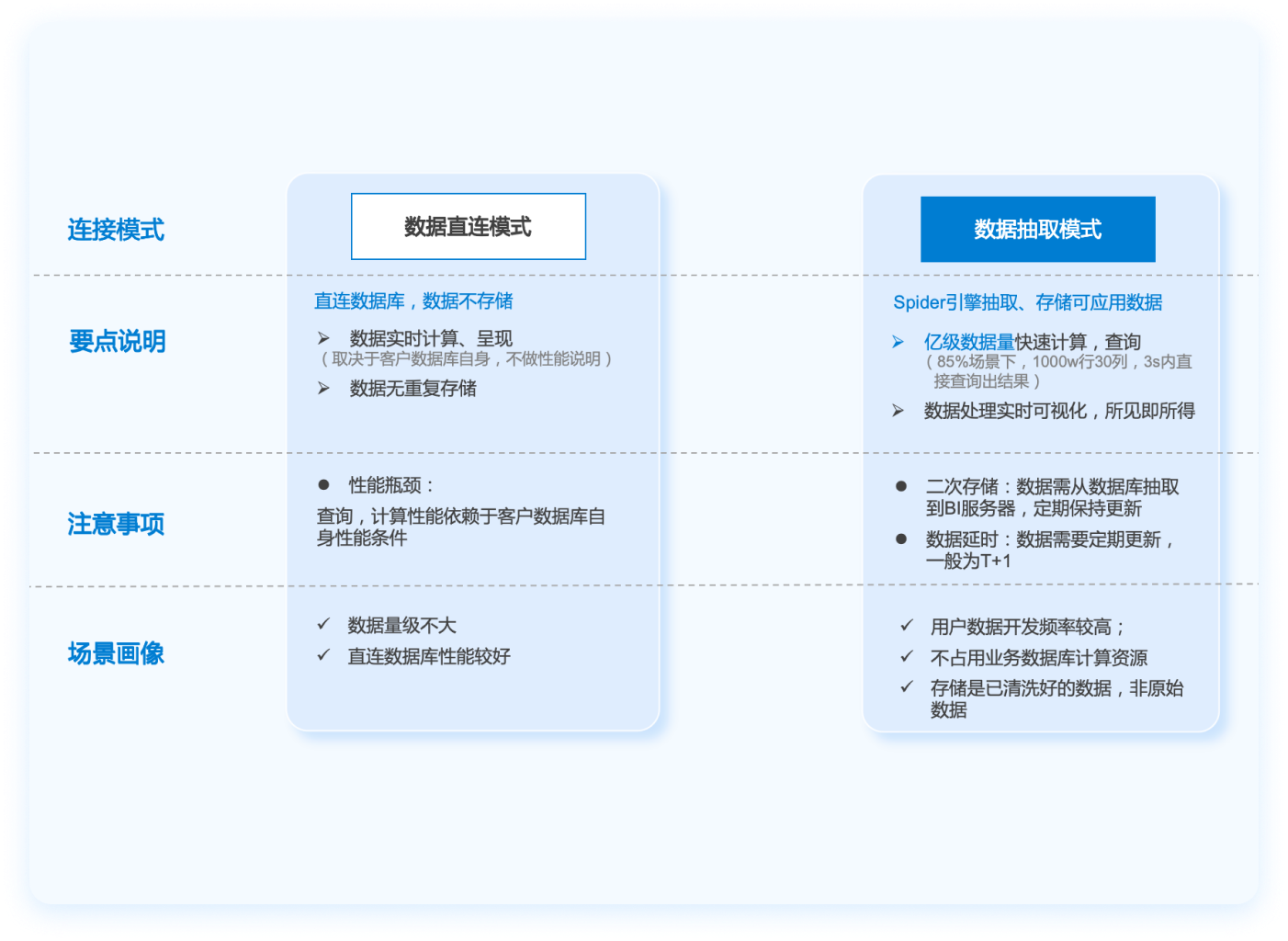
基于帆软自研引擎的直连模式和本地模式,可支撑Bl数据分析的各种应用场景
抽取数据的存储是以列为单位的,同一列数据连续存储,在查询时可以大幅降低I/O,提高查询效率,并且连续存储的列数据,具有更大的压缩单元和数据相似性,可以大幅提高压缩效率。
为了减少网络传输的消耗,避免不必要的shuffle,利用Spark的调度机制极现数据本地化计算。在知道数据位置的前提下,将任务分配到拥有计算数据的节点上,节省了数据传输的消耗,完成巨量数据计算的秒级呈现。
位图索引即Bitmap索引,是处理大数据时加快过滤速度的一种常见技术,并且可以利用位图索引实现大数据量并发极算,并指数级的提升查询效率,同时我们做了压缩处理,使得数据占用空间大大降低。
直连模式下会直接和数据库对话,性能会受到数据库的限制,因此引入encache框架做智能缓存,以及针对返回数据之后的操作有多级缓存和智能命中策略,避免重复缓存,从而大幅提升查询性能。
指标中心是FineBI7.0新增的重要能力,指标维度和数据集一样是用户分析数据的起点,使用指标做分析可有效减数据口径争议、提高指标复用度,进而减少数据冗余和混乱,使用数据集可以通过灵活的数据处理进行深度的业务自助分析,FineBI支持企业按需选择这两种数据使用路径。
当指标直接服务于企业经营管理和业务决策时才能充分发挥价值,停留在数据治理平台里的指标难以被业务用户理解、难以被管理者看到,因此必须再转化为数据表、指标卡、看板才能被用于分析,FineBI打通了指标平台和分析平台,让指标分析的链路更简短,从而充分发挥指标建设的价值。
FineChatBI是基于FineBI平台的应用,借助FineBI强大的数据分析底座有如下优势:1)同步BI平台原有用户信息,数据权限可管可控,2)基于BI平台的数据生成问答结果,所有数据结果的计算过程可透明,准确度可靠,3)可直接生成BI仪表板,支持用户做深入的分析和调整。
帆软提供了海量业务分析模板供用户参考,用户可在FineBI的模板市场一键应用行业标杆案例,不仅可以启发分析方向,还可以提升约60%的分析场景搭建效率。
若您有更多关于FineBI的疑问,请联系帆软销售:商务咨询,或拨打400-811-8890
功能免费体验,内置400+分析模板带您快速上手!
免费试用扫码添加专属售前顾问
免费获取更多行业资料
 CN
CN