电话咨询:400-811-8890
电话咨询:400-811-8890
电话咨询:400-811-8890
电话咨询:400-811-8890
作者:Jenny.Zhang
发布时间:2022.11.1
浏览次数:6,033 次浏览
说起数据质量,其实是一个很宽泛的问题,类似于写数据建模一样,是一个抽象概念为主的事情,对于程序员群体来说,总是难以解答和回答的。
这里针对数据质量等类似的、在数据仓库平台中必须提及的概念,提供一种解答的思路,就是架构推导理论。
先说一下基本的架构推导理论:架构 = 组件模块+关联关系+约束&指导原则。
我们用一张图来解释架构在系统中的作用:
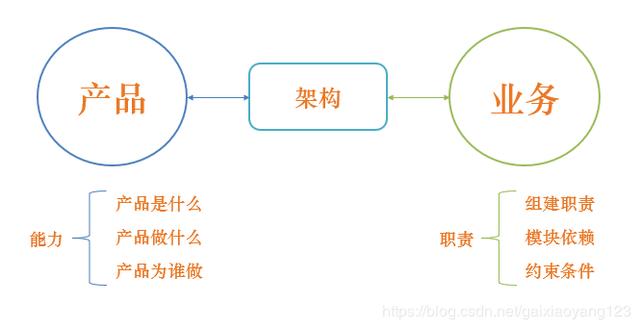
从上图可以看出,架构是介于产品和业务之间的桥梁,从任意维度出发,通过架构,能够推导出另一维度的相关信息。因而,架构的推导也有两种思路:自顶向下和自底向上。
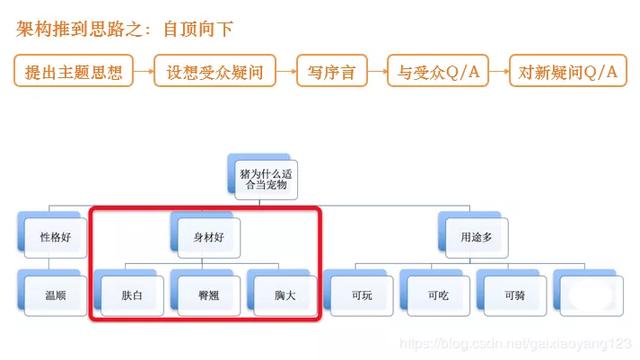

通过这两种方式,我们可以先采用自底向上的方式,来分拆产品描述的细节,总结出初步的观点,再按照程序员的思路进行自顶向下的拆分,最后再进行一轮自底向上的总结,基本上就可以确定一套系统应该有的架构和细节。
说了这么多,其实核心思想很简单,针对任何一类问题,都有两种思考它的方法:自顶向下和自底向上。在此基础上,可以多次组合这两种方法,来得到一个问题完整的多方面回答。
那么数据质量应该怎么思考,首先从程序员的角度出发,进行自底向上总结。
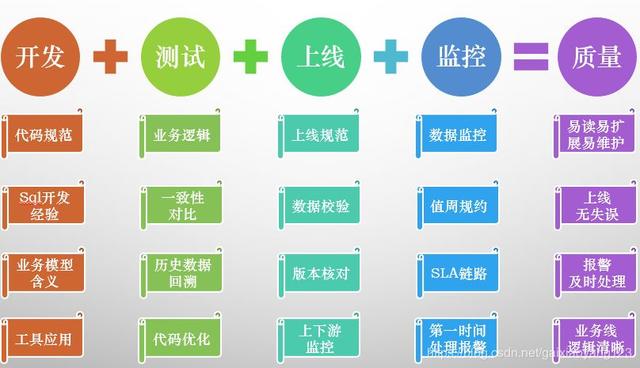
第一步,从程序员的日常工作出发。数据仓库工作中,开发占了绝大部分的比重,因此代码规范肯定是非常有必要的,其次应该是具体技术的应用细节,例如注意数据倾斜等问题,再次要对业务的概念非常熟悉,避免与产品思路上的差异,最后就是要熟练应用各种开发工具。把这些事情的各种细节做总结,升华一下概念,就是开发质量。
第二步,从配合人员的工作出发。如果团队稍微大一些的话,肯定有相应的测试或者运维人员,对于我们开发的代码和运行进行配合。例如业务逻辑的二次check、数据的运行结果之间一致性是否有保障,同时如果已开发的过程存在了问题,如何回溯历史数据、优化老代码也属于这个范畴。总结一下,就是需要测试的配合。
第三步,从流程角度出发避免人为失误。基本上正规一些的公司都会强调上线规范,做好数据校验、回滚方案、上下游监控等工作。
第四步,从维护角度出发及时发现问题。数据仓库其实最主要的一个问题,就是针对每一个问题,都要有相应的开发人员来检查问题,因此要有详细的值周规约,能够在第一时间出问题时有人介入。此外还需要配合各种完善的报警与监控平台,针对数据仓库日常的整体状况进行一个全面的监控。
总结这四个细节问题的汇总,可以得到四个角度的回答:易读易扩展易维护;上线无失误;报警及时处理;业务逻辑清晰。这四条其实就可以看作是数据质量的一个大的概念,用一张图来总结更为清晰一些:
虽然说从程序员的角度出发,数据质量的问题描述的已经比较清晰了,但是对于非数据开发的程序员,以及产品和运营人员来说,这些还是有些难以读懂。因此很多时候要求我们用更抽象的角度出发,来进行问题的拆解。
这里常见的描述问题方式,参照CAP与BASE原则,我们可以仿照别人的概念,来组织和细化一个属于我们自己的概念,这里也算是自顶向下思路的一种实现。
从笔者自身的角度出发,我总结了大概八条原则,详情如下:
但其实总结出理论还是很抽象,一些Boss或者Leader会要求你结合具体的场景来解释这些概念,这个时候从一次普通的业务开发出发,完整的阐述从数据采集、同步、开发,到最后的数据展现,我们都做了哪些事情,就十分有必要了,这也是从架构角度看数据质量如何保障的具体实现。
首当其冲的是业务信息的变更,例如增加某种统计字段,或者是重新改变某种指标的计算方式。业务信息的变化不仅是需要开发人员的主动介入,也需要平台工具的相关支持。例如Mysql数据库表发生信息变更时,通过Canal等组件可以感知数据表的DDL变化情况,离线根据DDL信息变更对应Hive表的信息。
其次是代码提交的校验环节,因为数据质量是一个很冰冷的词汇,代码出了问题就是质量不好,因此如何最大程度上避免人为错误,就成了数据质量保障的重要工作。
还是两个方面的思路,一个是交叉检验,既然一个人容易出问题,那么两人及以上来校验,出错的概率就会大幅降低,因此需要搭建一个可行的测试环境,如果没有,可以在线上平台搭建一个相同的测试表,导入少量的数据,这时安排测试人员介入逻辑的检查,并且做相应的回归测试。
另一个是进行静态的SQL代码检查,针对大表扫描、空值校验等检查,提示开发人员对应的错误风险。在数据采集环节,还可以加入一些与具体业务紧密相连的监控规则,例如订单拍下时间不大于当天时间,等等。
再次是搭建一些机制完善的辅助平台,例如可以调整任务优先级的调度平台,例如可以准时发现问题并提醒的报警平台,例如可以检测任务依赖死锁的开发平台,等等,针对数据的延迟监控、作业调度的合理性等情况做辅助的技术保障。
最后是要有完善的开发组织工作,针对每一次出现的数据故障,都得安排对应的事件回顾,每周安排例行会议进行典型开发代码的Code Review,有详细的数据问题应对手册以供新入职的开发人员熟悉,等等。
既然提到了数据质量,那么质量便有好坏的区分,像数据平台百万级的数据表,总有高质量与低质量的区分,这时候需要进行相应的数据资产评估,高质量的表需要更高的优先级来进行处理。
这里提供一些常见场景:

商业智能BI产品更多介绍:www.finebi.com