电话咨询:400-811-8890
电话咨询:400-811-8890
电话咨询:400-811-8890
电话咨询:400-811-8890
作者:FineBI
发布时间:2023.9.14
浏览次数:2,682 次浏览
大数据是一个体量特别大,数据类别特别大的数据集,并且这样的数据集无法用传统数据库工具对其内容进行抓取、管理和处理。大数据首先是指数据体量(volumes)大指代大型数据集,一般在 10TB 规模左右,但在实际应用中,很多企业用户把多个数据集放在一起,已经形了 PB 级的数据量;其次是指数据类别(variety)大,数据来自多种数据源,数据种类和格式日渐丰富,已冲破了以前所限定的结构化数据范畴,囊括了半结构化和构化数据。接着是数据处理速度(Velocity)快,在数据量非常庞大的情况下,也能够做到数据的实时处理。最后一个特点是指数据真实性(Veracity)高,随着社交数据、企业内容、交易与应用数据等新数据源的兴趣,传统数据源的局限被打破,企业愈发需要有效的信息之力以确保其真实性及安全性。
基于此背景,在未来几年内大数据技术将不断革新,日趋强大,市场前景也是一片大好,随之踊跃出一大批以"大数据分析平台展示"的互联网公司,其中帆软finebi的产品尤为突出。
1.FineBI Spider 高性能计算引擎,以轻量级的架构实现大数据分析
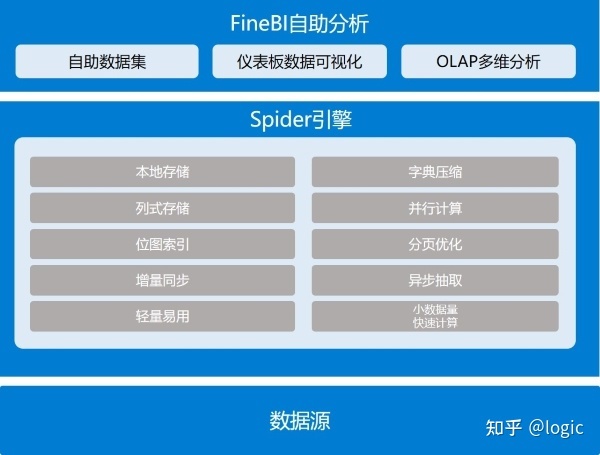
2.FineBI Spider 引擎支持实时数据与抽取数据两种模式,更可无缝切换
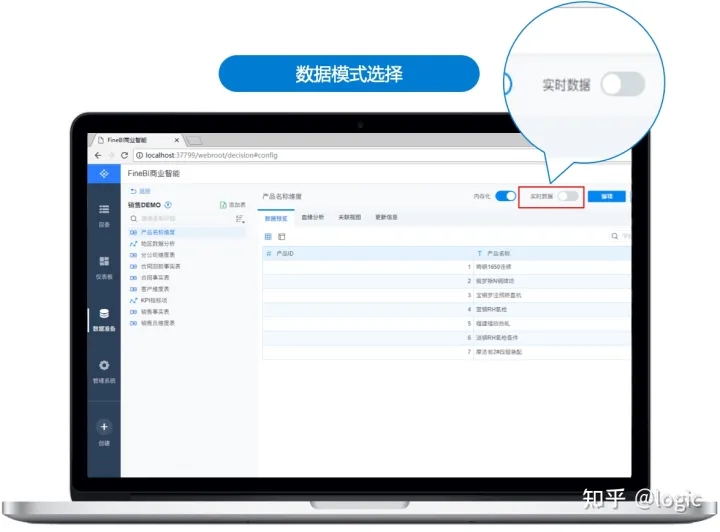
3.FineBI Spider 引擎的高性能可轻松实现亿级以内的数据秒级呈现
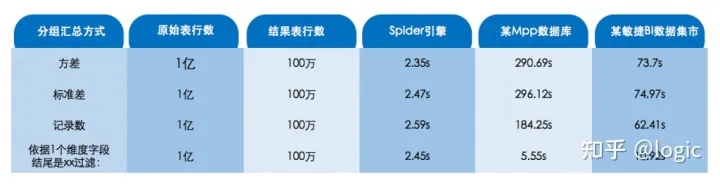
大数据测试场景举例(1 亿条数据量):分组汇总(含第三方对比)
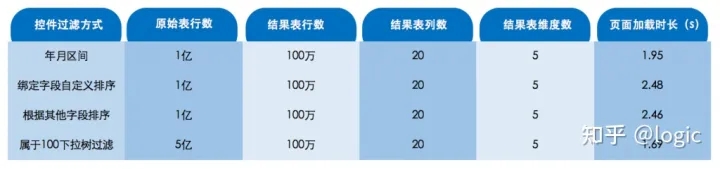
大数据测试场景举例(1 亿条数据量):控件过滤
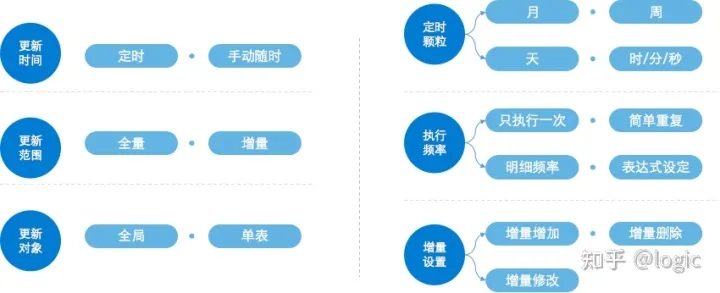
4.FineBI Spider 引擎支持灵活的数据更新策略,让数据准备更加高效
通过FineBI Spider引擎进行前期的数据导入,数据清洗和数据加工,然后通过仪表板组件可视化分析功能,快速完成各类维度和指标的数据管理驾驶舱的布局组合分析。从而实现晋城高速综合管控大数据展示平台。
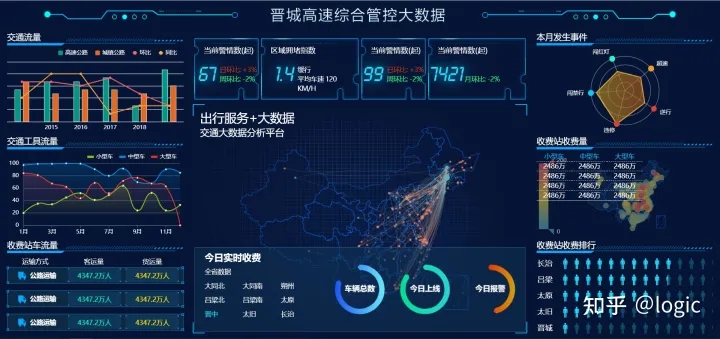
无性能,不数据。无论是大数据还是小数据,都必须有高性能做支撑。帆软FineBI在产品的稳定性,以及并发数、超大数据量处理上,都有着绝佳的表现,这都归功于帆软 FineBI所采纳的性能处理方案。帆软FineBI的 Spider 计算引擎可以预先抽取数据进行离线计算,来支撑快速灵活的前端分析给用户极佳的性能体验。这稳定地支撑着帆软大数据平台展示技术和帆软可视化数据平台。
商业智能BI产品更多介绍:www.finebi.com